从根儿上理解 MySQL - 页总结
页结构
由于 MySQL 的真实数据是存储在磁盘, 因此在读写数据是会涉及磁盘 IO, 为了更高效率的读取, MySQL 设计页结构, 每次交互以页为单位读取到内存. 页的大小一般为 16KB
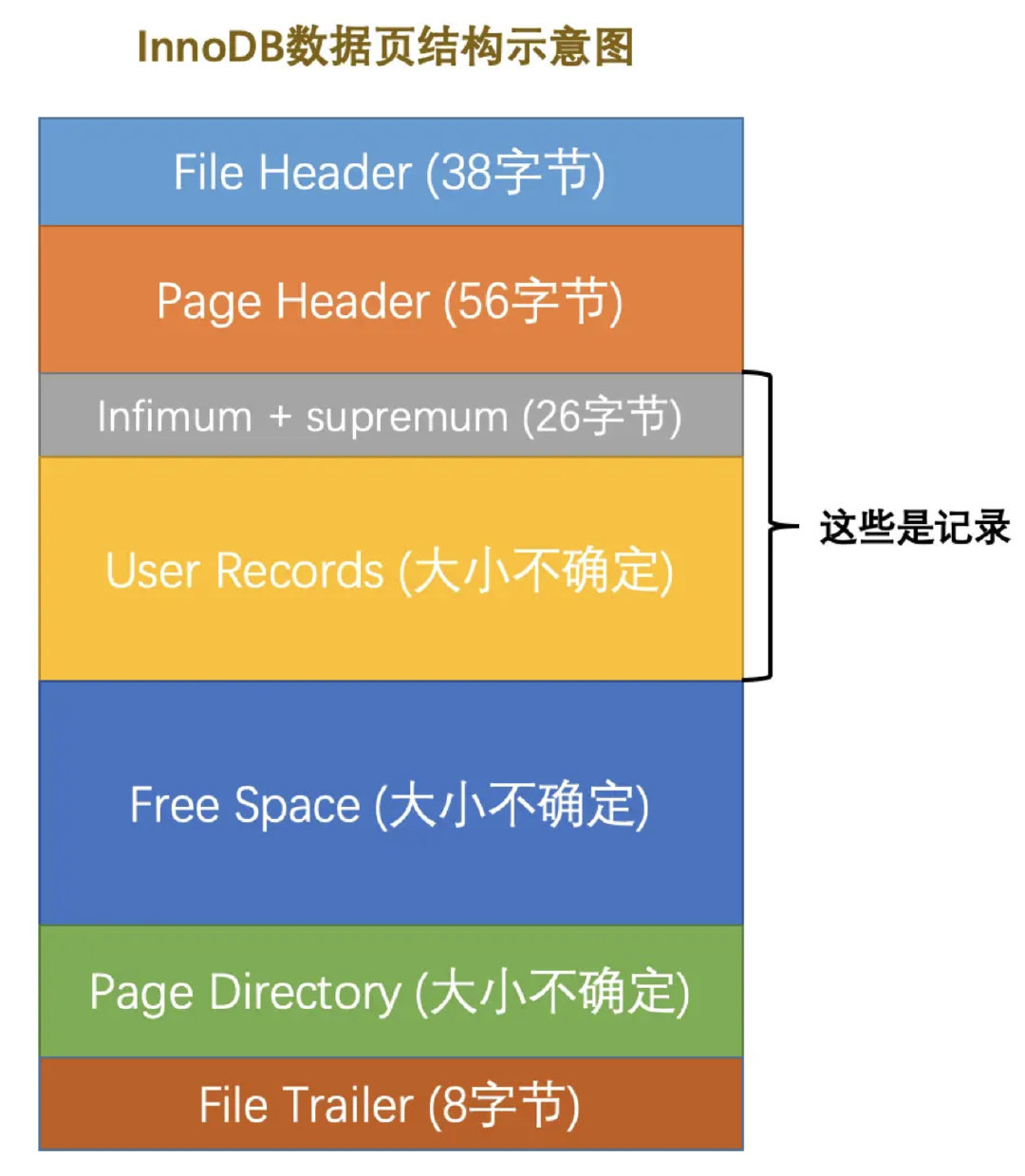
一个数据页可以被大致划分为7个部分
File Header,表示页的一些通用信息,占固定的38字节。
Page Header,表示数据页专有的一些信息,占固定的56个字节。
Infimum + Supremum,两个虚拟的伪记录,分别表示页中的最小和最大记录,占固定的26个字节。
User Records:真实存储我们插入的记录的部分,大小不固定。
Free Space:页中尚未使用的部分,大小不确定。
Page Directory:页中的某些记录相对位置,也就是各个槽在页面中的地址偏移量,大小不固定,插入的记录越多,这个部分占用的空间越多。
File Trailer:用于检验页是否完整的部分,占用固定的8个字节。

上述的行格式即为 User Records的一部分
新生成的页并没有 User Records, 当插入数据时, 会从 Free Space 申请, 如果 Free Space 的空间全部被替换掉, 则说明该页满了, 需要申请新的页
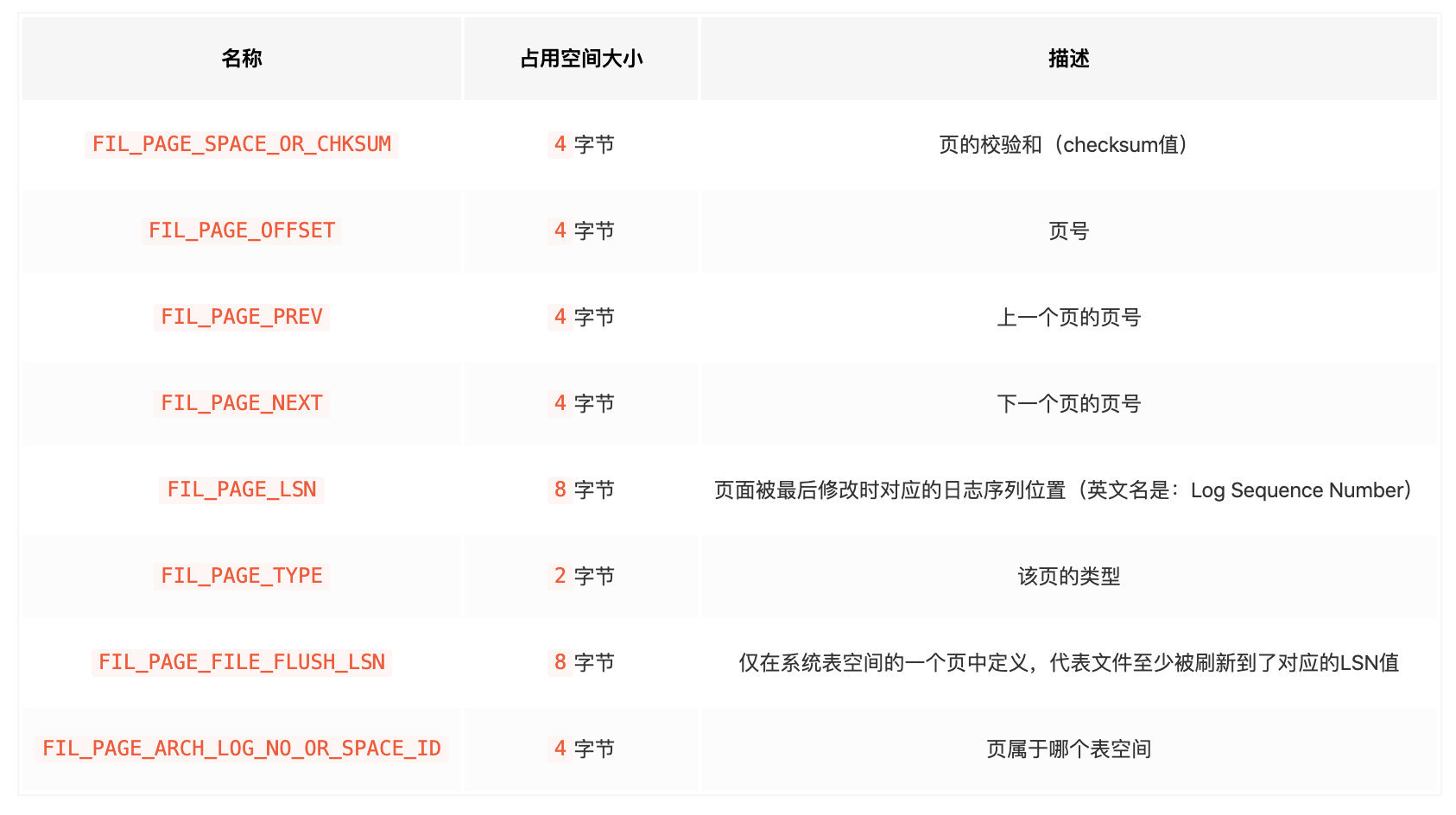
File Header (文件头部)
文件头部表主要关注点在于页号, 上一页的页号和下一页的页号. 构成了双向链表
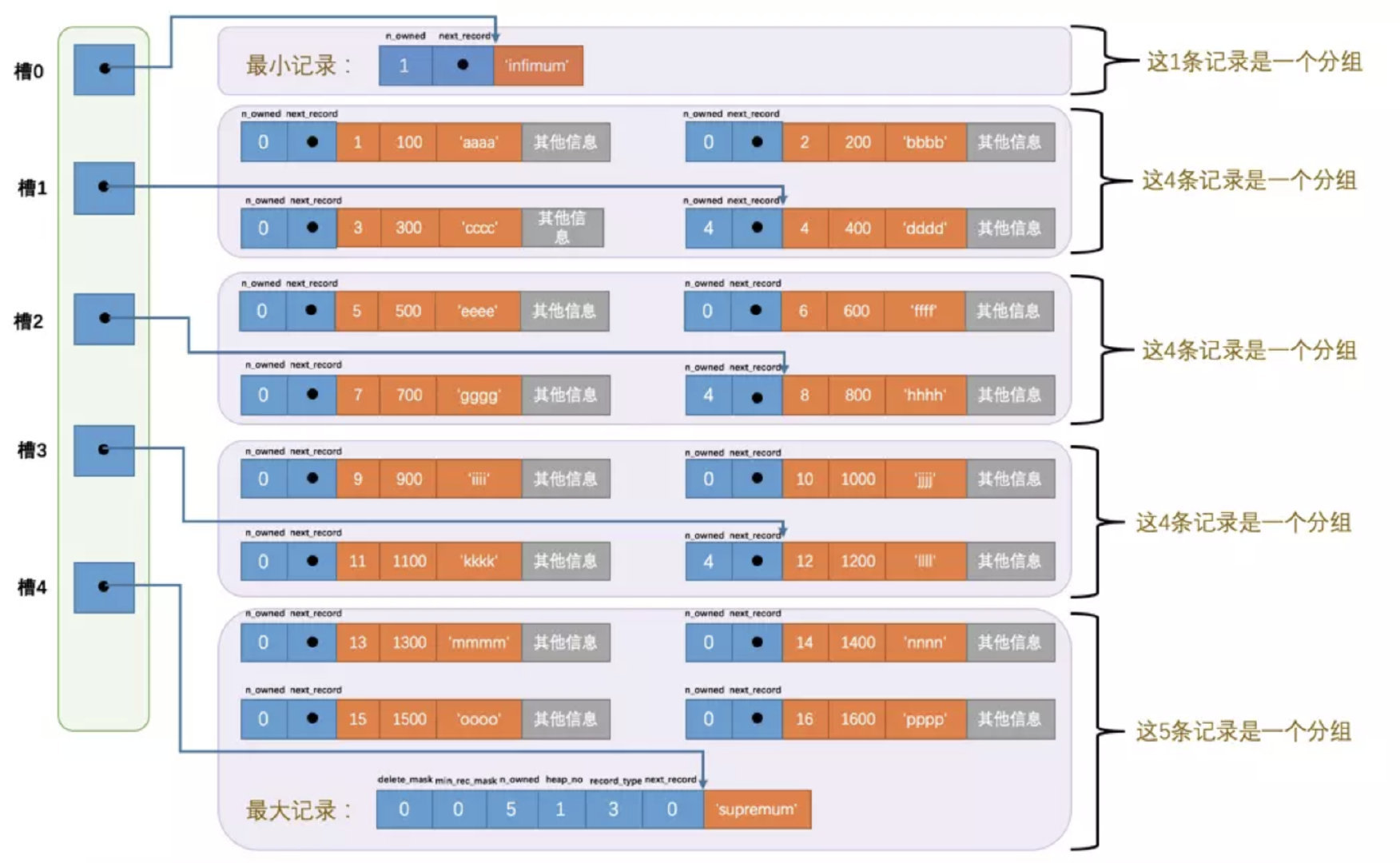
Page Directory (页目录)
从 select * from table wher id = 1 讲起
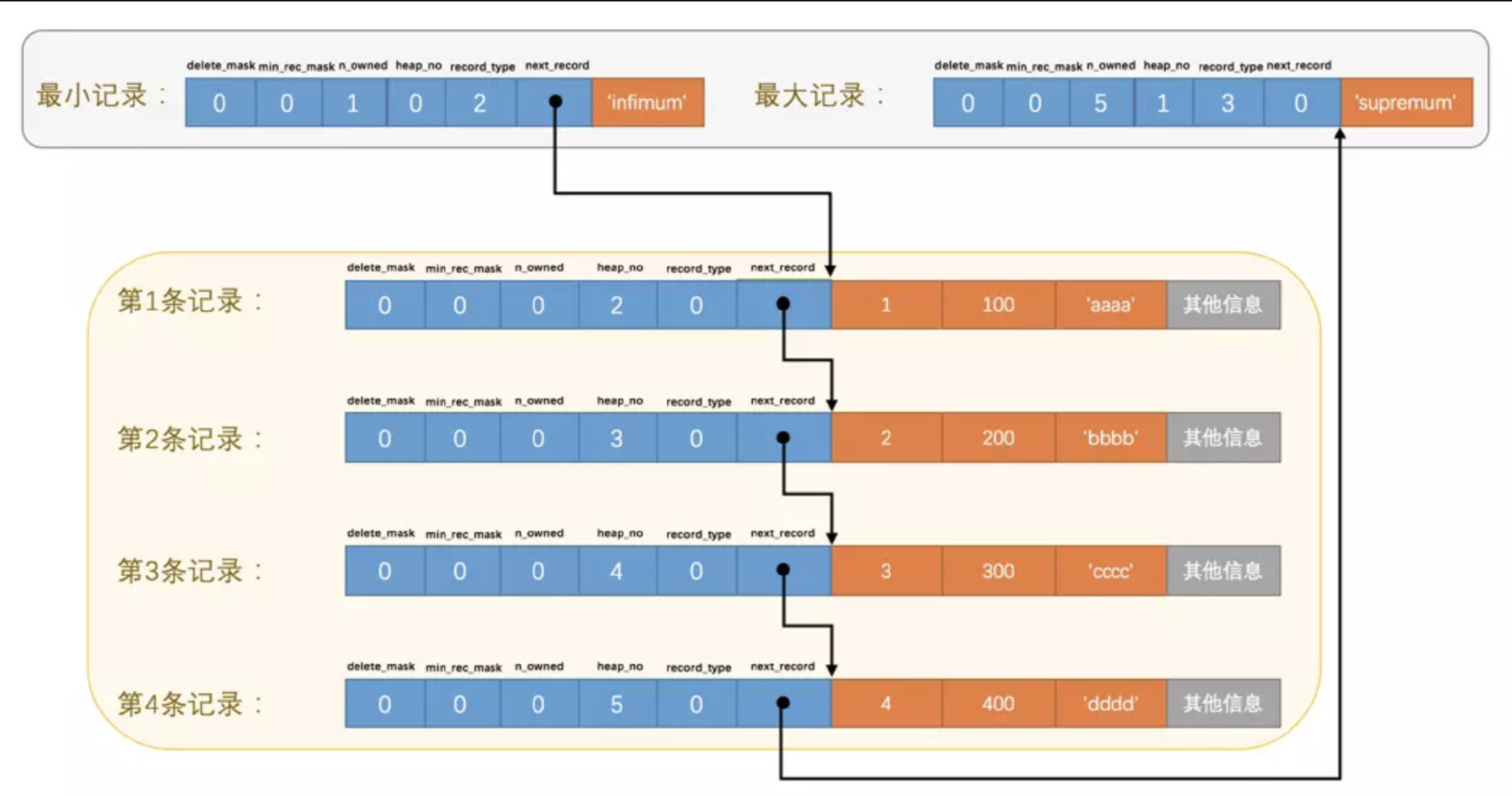
比较笨的方式会从最小记录开始遍历往下找, 知道找到 next_record = 0MySQL 的优化点在于新增了一个目录, 利用二分查找优化
- 通过二分法确定该记录所在的槽(实际是找到确定的槽, 遍历该槽的上一个槽或者当前槽)
- 通过记录的next_record属性遍历该槽所在的组中的各个记录
1 | |
行格式
行格式主要分为四种类型Compact
、Redundant、Dynamic和Compressed. 主要理解 Compact
Compact 行格式
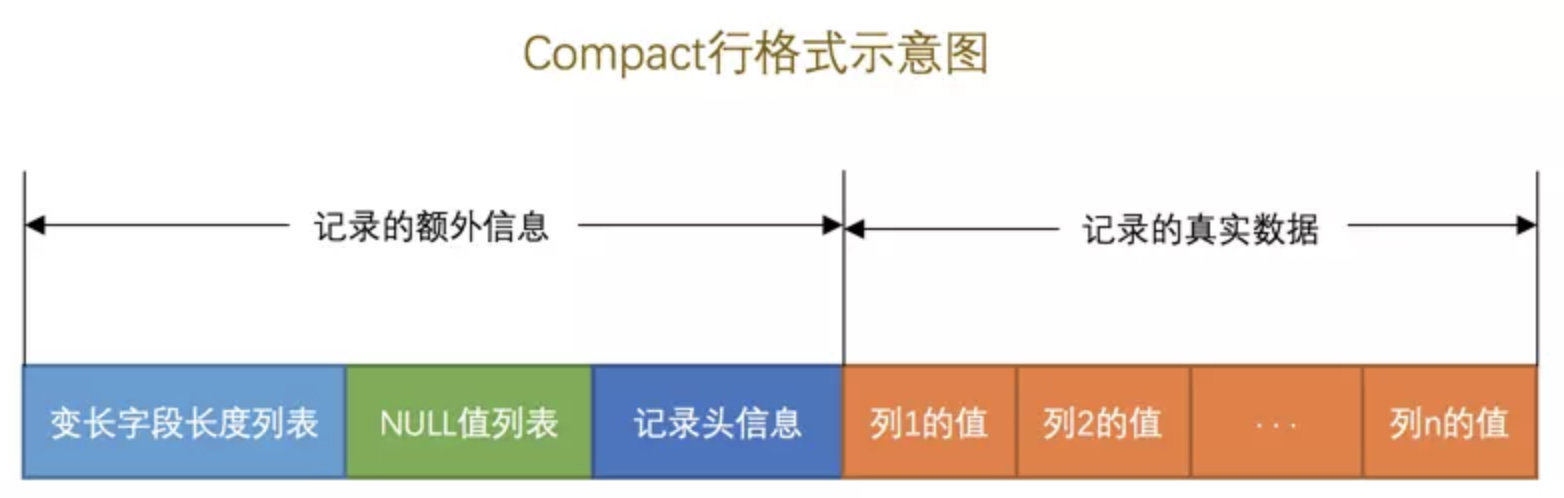
行格式主要分为记录的额外信息, 记录的真实数据
变长字段长度列表
变长字段长度列表存储的是变长类型的真实数据的占用字节数(逆序).
如果该表没有变长类型, 则无变长字段长度列表
变长字段长度列表只保存 NOT NULL列, 如果该列允许为 NULL, 则不会保存
1 | |
NULL 值列表
NULL 值列表只统计哪些字段允许为 NULL的值状态(逆序)
如果该表没有允许 NULL 列, 则无 NULL 值列表
MySQL规定NULL值列表必须用整数个字节的位表示,如果使用的二进制位个数不是整数个字节,则在字节的高位补0
二进制位的值为1时,代表该列的值为NULL
二进制位的值为0时,代表该列的值不为NULL
1 | |
记录头
这一部分牵扯的内容较多
大致可以看一下删除标识(删除是并非真正删除, 只是修改表示), 下一条记录位置(B+树特性)
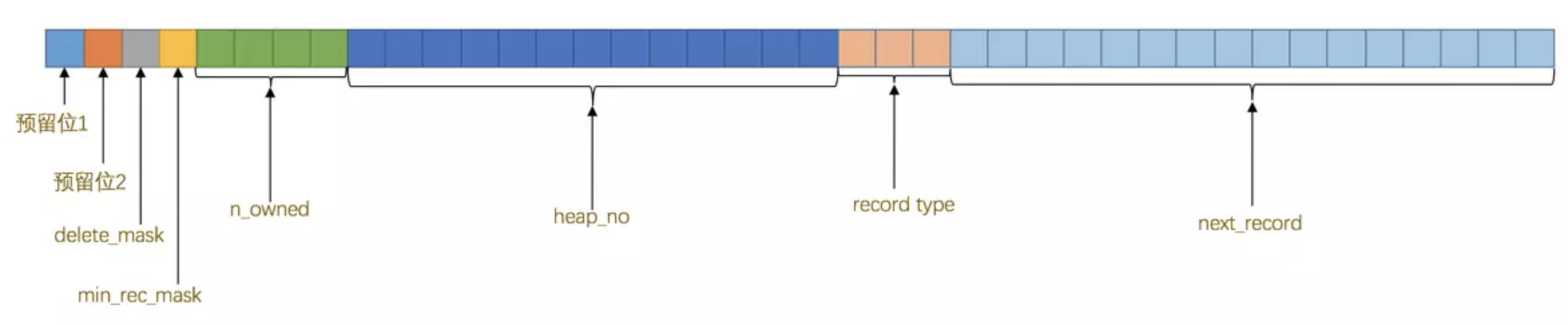
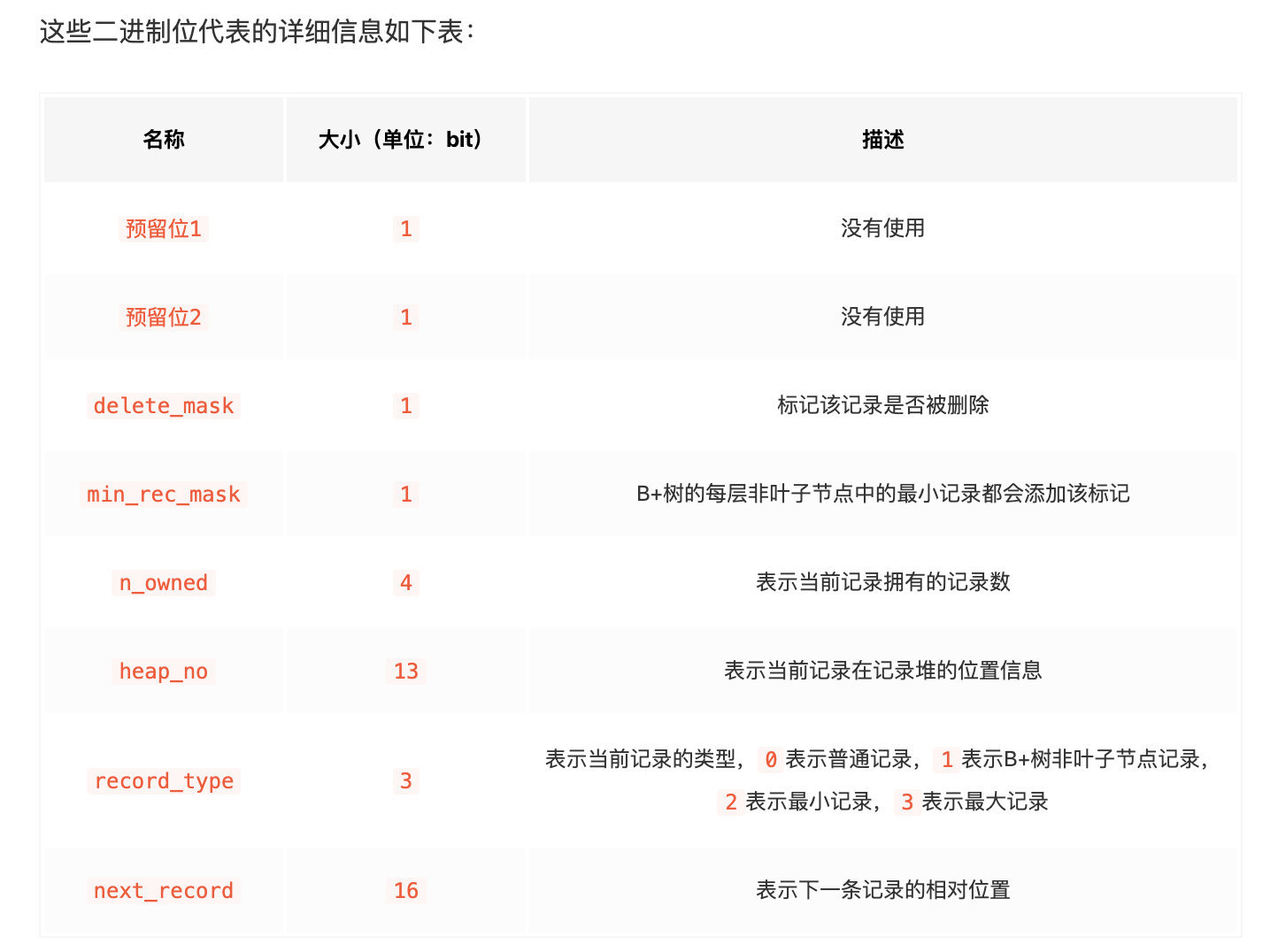
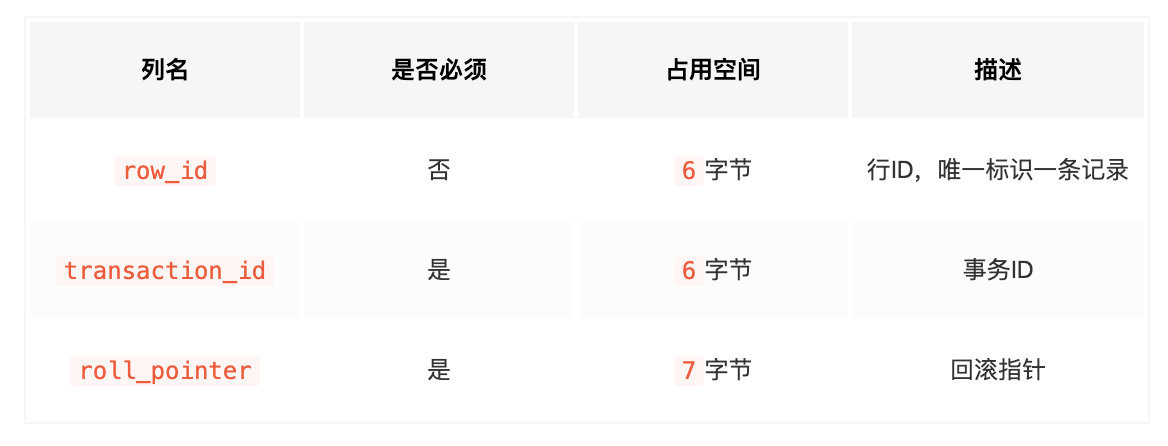
除了这些详细信息, 还会有 MySQL 自动添加的隐藏列
实际上这几个列的真正名称其实是:DB_ROW_ID, DB_TRX_ID, DB_ROLL_PTR, 为了美观才写成了row_id、transaction_id和roll_pointer
row_id: 有主键使用主键, 没有主键有唯一键使用唯一键, 没有则自动生成
transaction_id: 事务 ID
roll_pointer: 回滚指针
行溢出
因为一个页占用 16KB, 16 * 1024 = 16384 字节, 而 varchar 最多可以占用65535, 不包括隐藏列和记录头信息
但是在我们使用 varchar 时, 会设置变长字段长度列表和 NULL 值列表
对于 NOT NULL, 只能使用65533字节 (两个字节用来表示长度)
对于非 NOT NULL, 只用使用 65532 字节 (两个字节用来表示长度, 一个字节用来表示 NULL 标识)
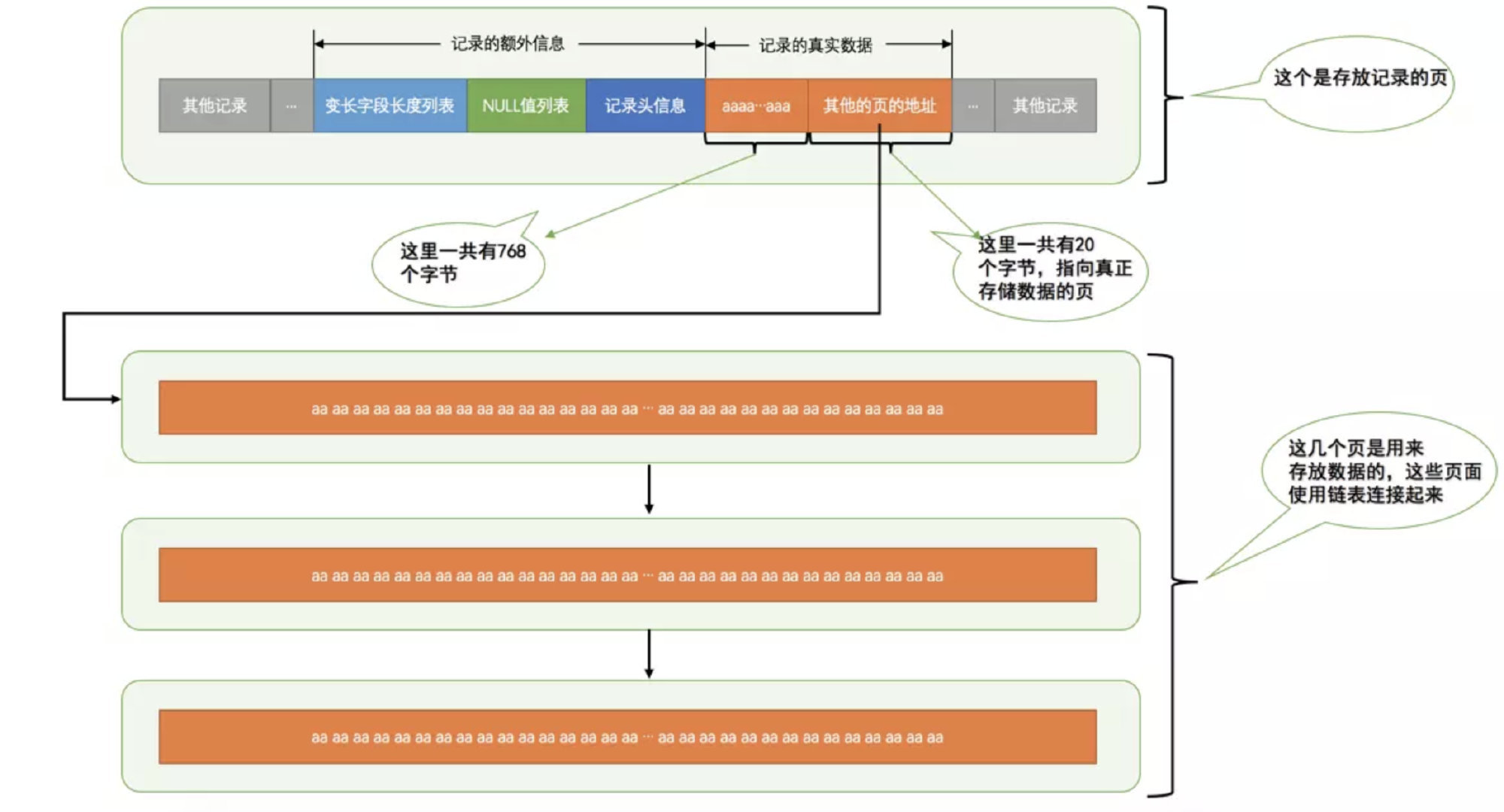
1 | |
行溢出的节点
综上所述, 我们知道在数据的占用字节数超过某个阈值就会发生行溢出, 那么行溢出的计算方式分析如下
ps: 截图来源于MySQL 是怎样运行的:从根儿上理解 MySQL(小孩子 4919)

其他
delete_mask
这个属性标识该条记录是否已删除
如果 MySQL 设计删除一条则执行磁盘删除, 会导致磁盘IO增加, MySQL 为了优化, 使用一个标识表示该记录已被删除, 如果有新的记录来, 会覆盖该条记录
原理: 删除数据时, 标识该记录已删除, 并且放入垃圾链表, 新的记录插入时, 先从垃圾链表中替换如果想要优化空间, 则执行 optimize table ‘name’ 即可
链表
页与页之间通过 File Header 双向链表连接上一条记录和下一条记录
页内数据记录 通过 next_record 单向链表连接下一条记录