从根儿上理解 MySQL - 缓冲池 & log
Buffer Pool
MySQL 在获取数据时, 是以页为单位. 每次读取一个页的数据放在内存中, 内存的哪里, 其实就是 Buffer Pool.
我们对页的所有处理都是在内存中处理, 至于刷盘时机, 在后续讲解中Buffer Pool 是 MySQL 启动是申请的一块连续内存, 默认 128M, 最小为 5M
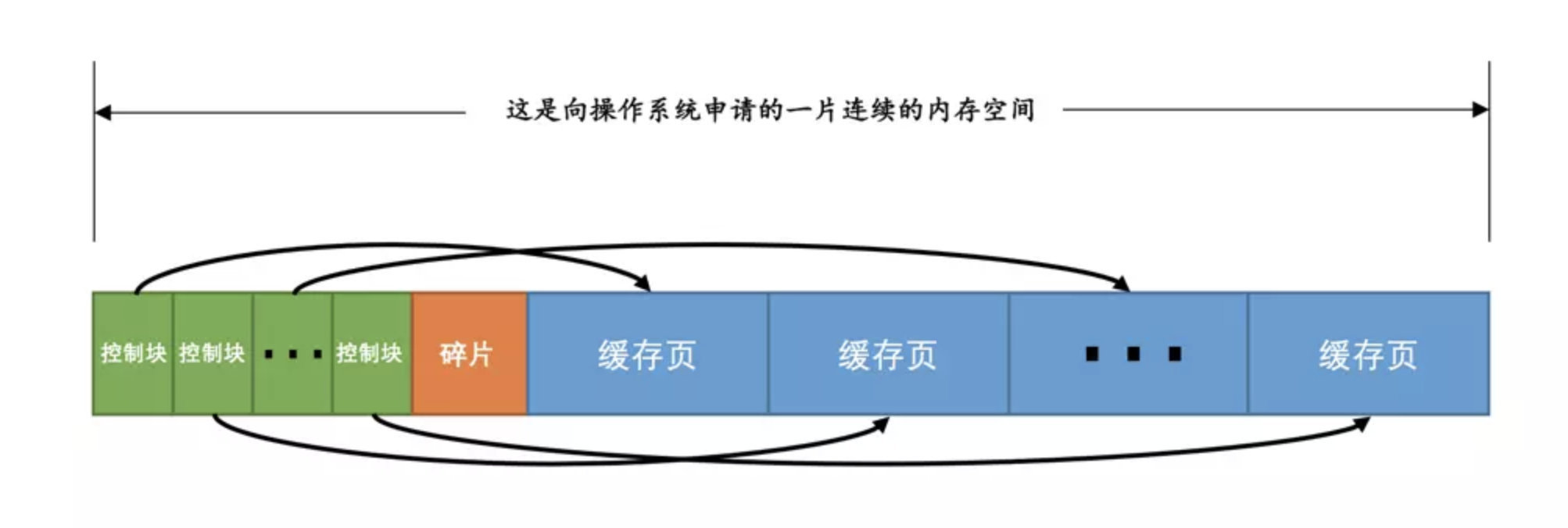
free链表
free 链表是把所有空闲的缓存页对应的控制块作为一个节点放到一个链表中, 记录哪些页是可用的
缓存页的 key 为: 表空间号 + 页号
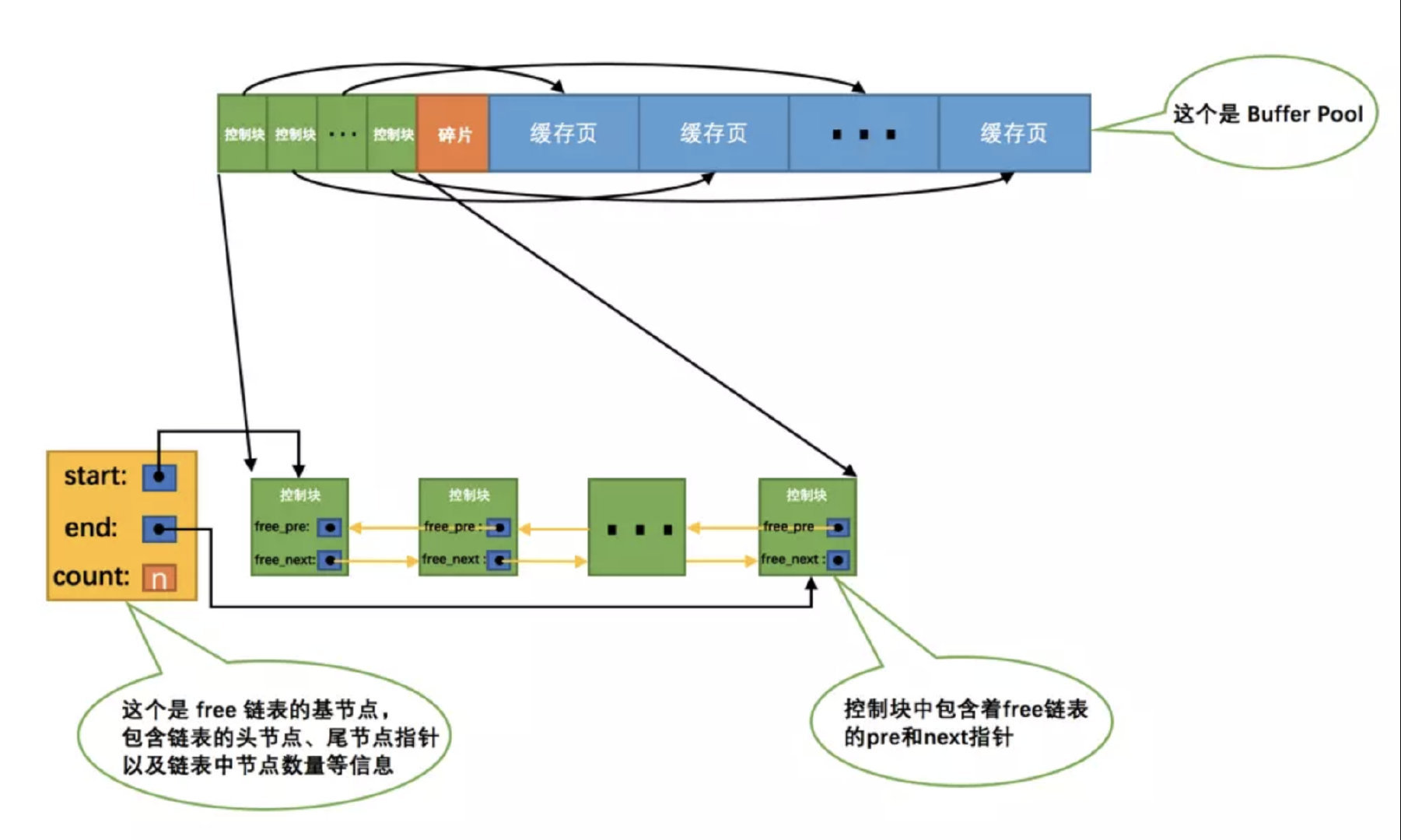
flush链表
如果修改了页, 此时内存中的页和磁盘的页就会不一致.
如果也发生修改就刷新到磁盘, 就会导致效率特别低下, 那么最好的方式就是一个链表管理发生修改的页, 在触发某种条件时刷新到磁盘. 这个链表就是 flush 链表
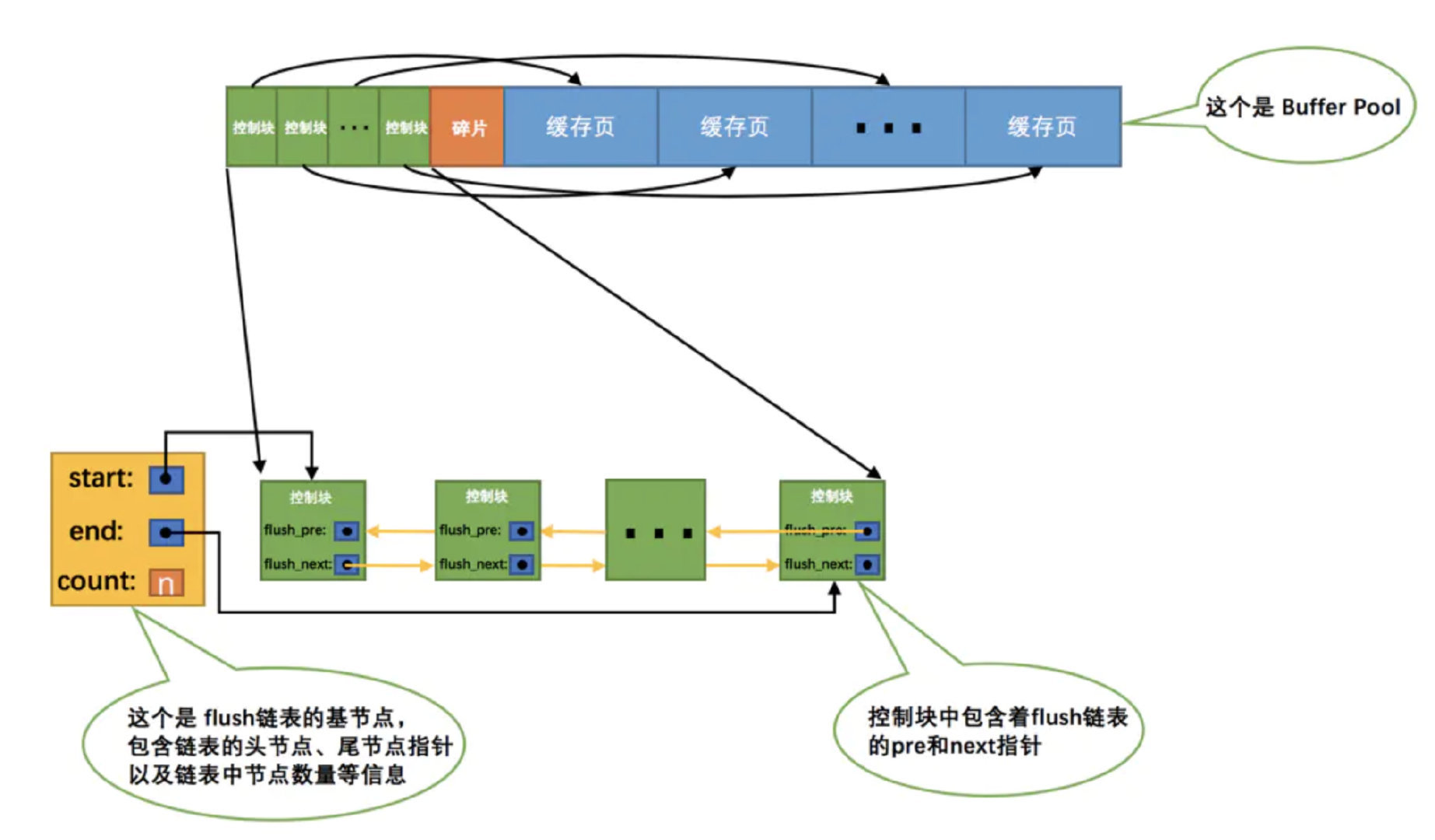
淘汰机制
我们 Buffer Pool 是有大小限制的. 但是每当我们读取页的时候, 就会把页加载进来. 一是很容易就撑满, 二是我们之所以设计 Buffer Pool 的原因就是更了更高效率的读取页, 充当缓存, 如果命中率很低, 那就没有太大的必要去维护 Buffer Pool. 那么 MySQL 是怎么提高命中率的和淘汰数据
淘汰数据是采用 LRU 列表
提高命中率是使用冷热数据, 冷数据为 young 区域, 热数据为 old 区域
那么对于全表扫描这种需要加载全部页的如果知道这些数据不应该放到缓存中呢?在对某个处在
old区域的缓存页进行第一次访问时就在它对应的控制块中记录下来这个访问时间,如果后续的访问时间与第一次访问的时间在某个时间间隔内(默认为 1s),那么该页面就不会被从old区域移动到young区域的头部,否则将它移动到young区域的头部.那么也就是说全表扫描拉取的也都是放在 young 区, 不会影响热数据, 因此并不会影响命中率
刷盘时机
- 后台线程定时刷新
- 参考 redo log
redo log
redo log 保证了 ACID 的 Durability (持久性)
MySQL 操作的基本单位是页, 如果只是一个很小的操作, 但是将一整个页的数据刷新到磁盘, 没必要. 如果通过记录修改内容日志, 刷新到磁盘, 效率会更高, 这个日志就是 redo log
页与页之间并不连续, 也就是随机写, 但是 redo log 是连续追加的, 性能很快
对于简单的操作, 可能只需要修改一个页中的一条数据
对于复杂的操作, 可能发生页分裂, 页拷贝和对索引的处理mini transaction mtr: 对于复杂的操作, 以组的方式写入 redo log(一种特殊的类型, 尾部有校验)

redo log 页
redo log 页又称为 redo log block
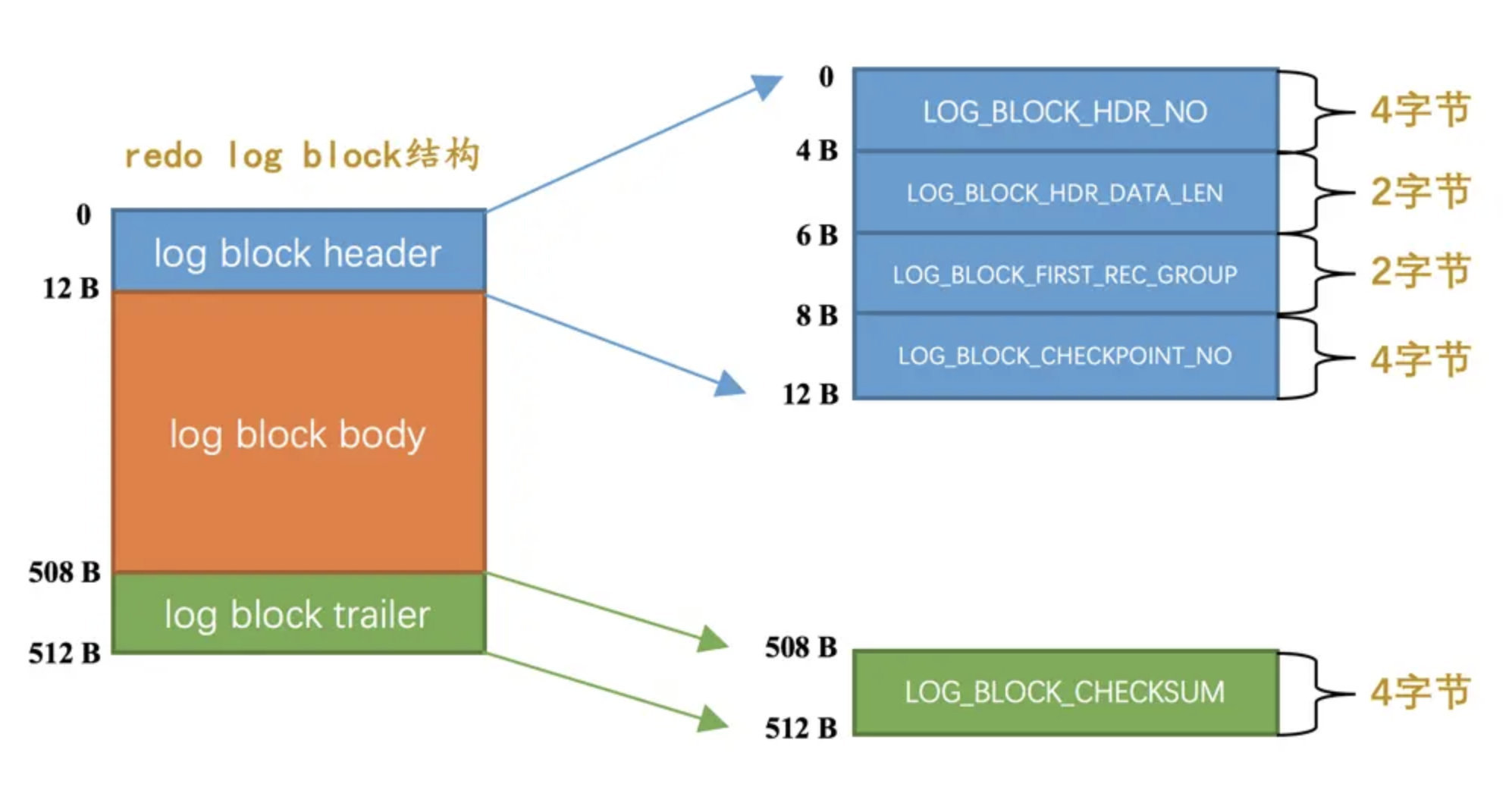
redo log 缓冲区
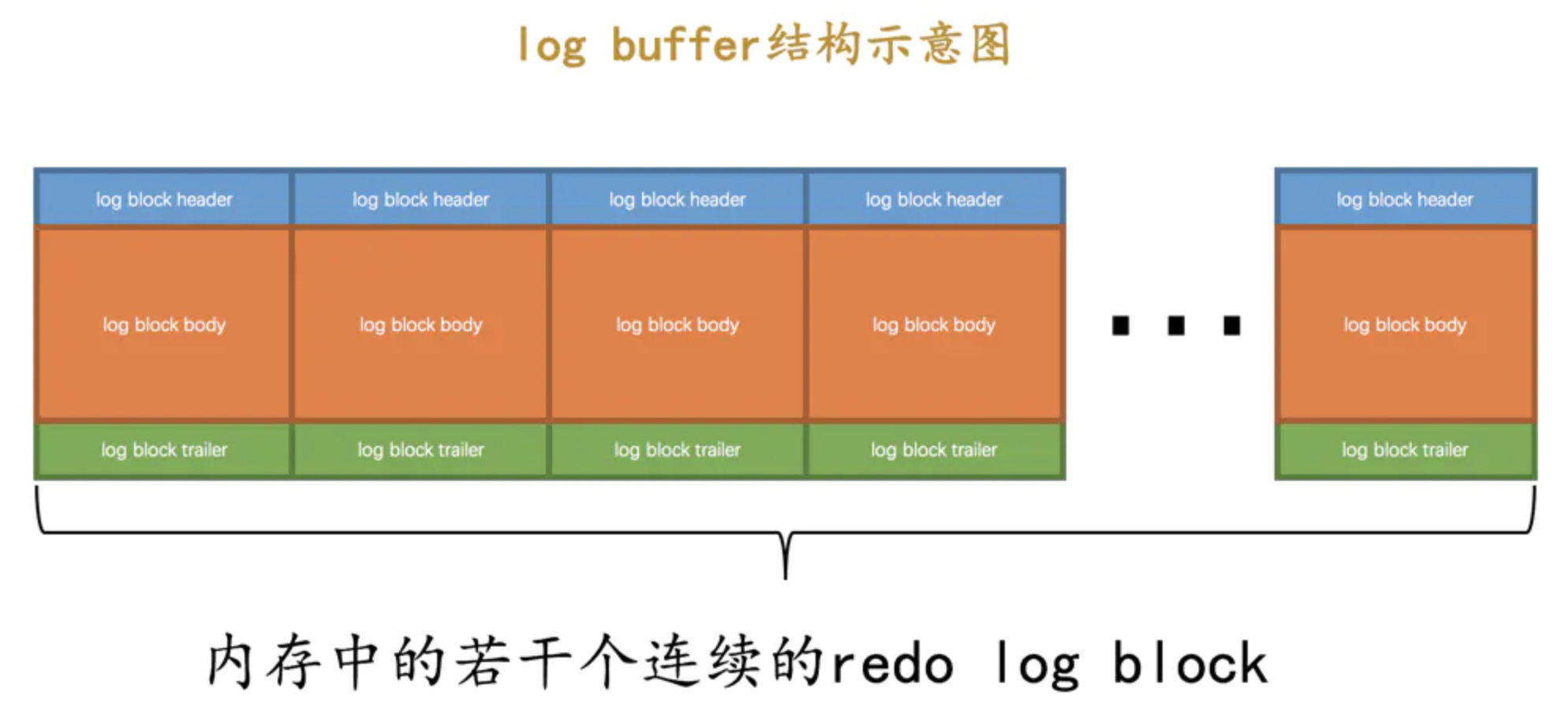
InnoDB 为了解决磁盘慢引入了 Buffer Pool, 同样 redo log 也有缓冲区
先写入 redo log 缓冲区, 然后根据刷盘时机写入 redo log
刷盘时机
log buffer空间不足时- 事务提交时
- 后台线程不停的刷 (平均一秒)
- 正常关闭服务器时
- checkpoint
日志文件组
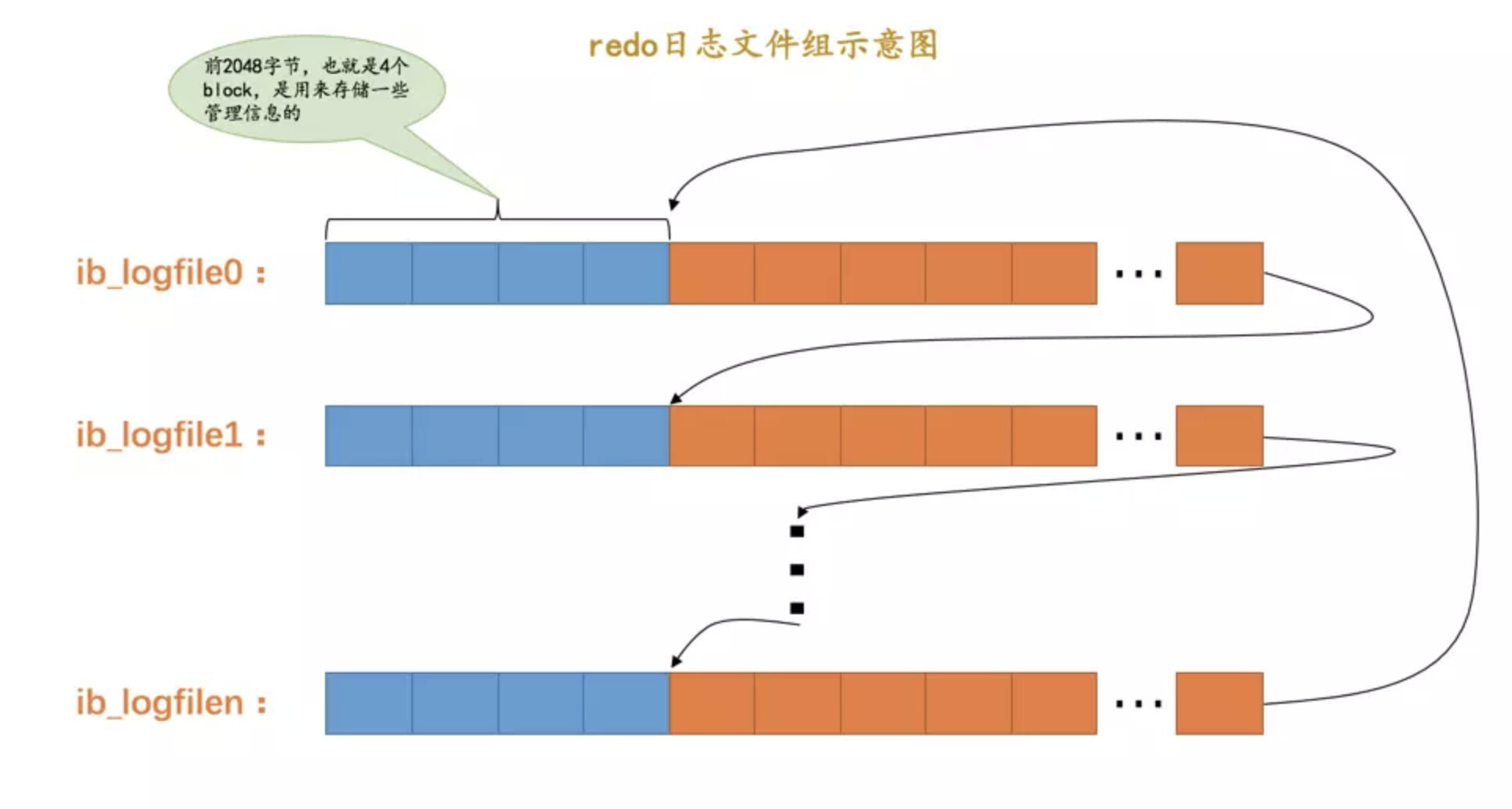
flushed_to_disk_lsn
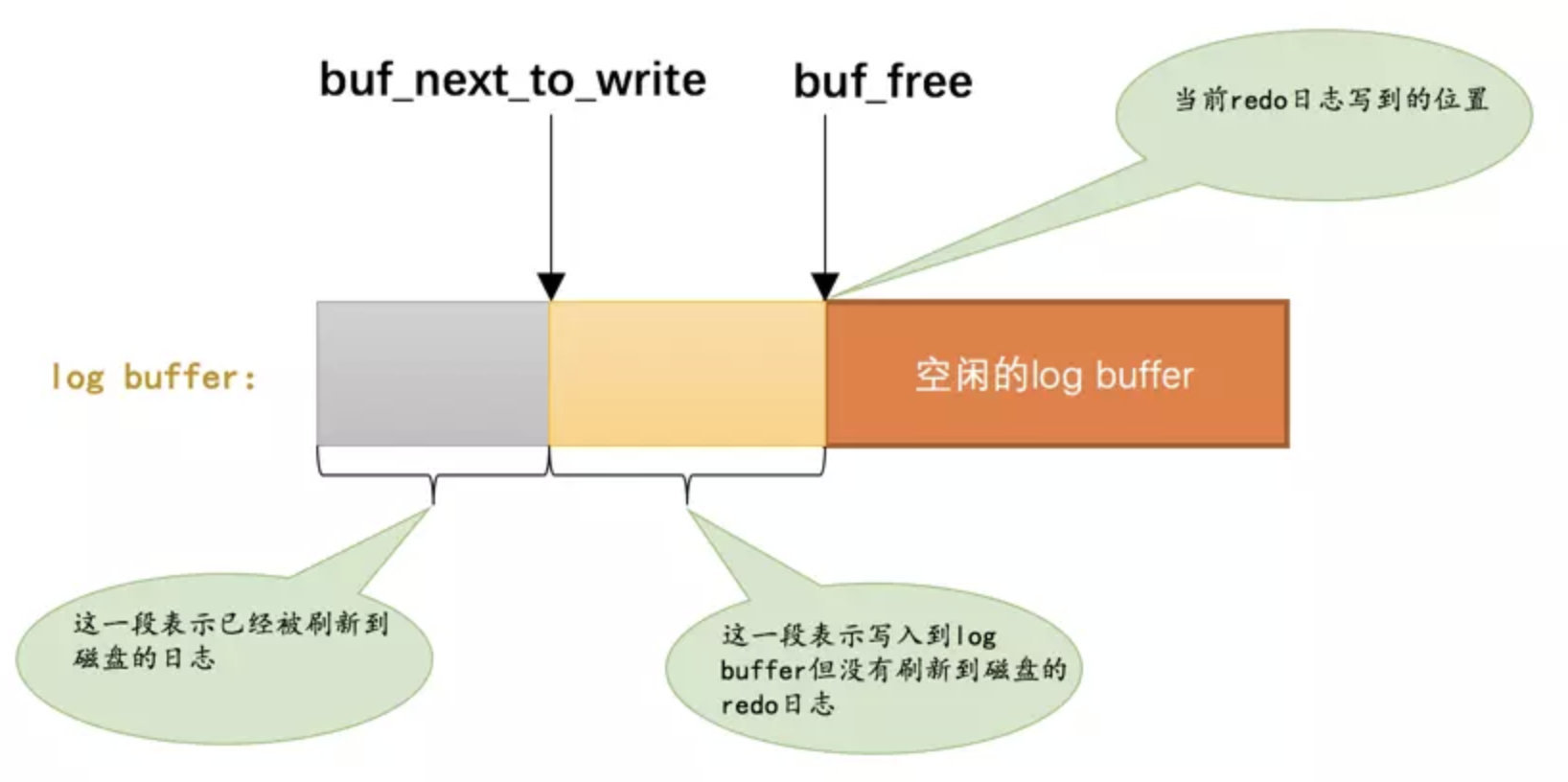
lsn: Log Sequeue Number, 记录已经写入的
redo日志量. lsn 增加是以实际写入的日质量来增加buf_free的位置为写入到 redo log buffer的偏移量(即为 lsn)
buf_next_to_write 的位置为实际已经刷新到磁盘的偏移量
如果两个值相同, 则说明所有的 redo log 都已经刷新到磁盘
flush链表中的LSN
我们知道一个
mtr代表一次对底层页面的原子访问,在访问过程中可能会产生一组不可分割的redo日志,在mtr结束时,会把这一组redo日志写入到log buffer中。除此之外,在mtr结束时还有一件非常重要的事情要做,就是把在mtr执行过程中可能修改过的页面加入到Buffer Pool的flush链表
checkpoint
上面我们已经记录了, redo log buffer写到的位置, redo log 写到磁盘的位置. 同理 redo log 写到磁盘之前的位置已经没有用了, 但是我们不能删除, 为什么? 因为我们只是把 redo log 刷新到磁盘, 但是页还没有刷新, 需要等到 flush 链表该页刷新到磁盘之后, 才能删除, 换句话说就是被覆盖. 那么这个可以被覆盖的位置就是 checkpoint
崩溃恢复
综上所述, 我们系统崩溃时, checkpoint 之前的页都已经刷新到磁盘的, 对于 checkpoint 之后的虽然 redo log 刷新到磁盘, 但是页不一定刷新到磁盘. 如何判断是否刷新到磁盘
恢复的起点: 最新的 checkpoint
恢复的终点: log block header未被填满的 block