从根儿上理解 MySQL - 索引总结
前提
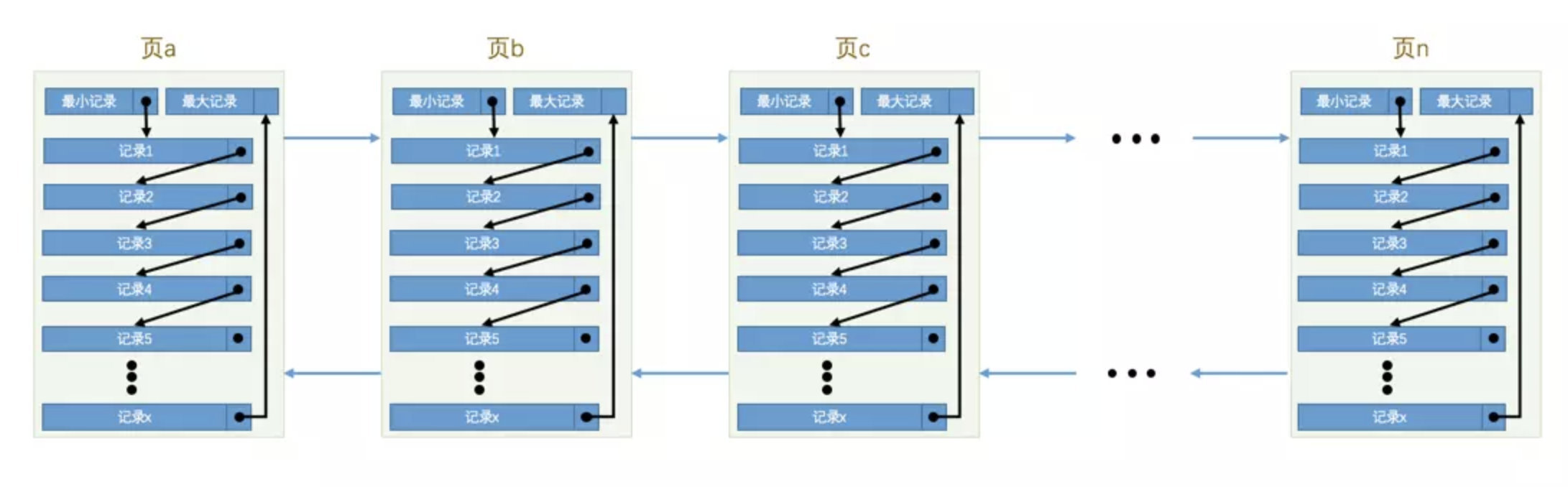
上一篇我们已经知道了 Innodb 的页的数据结构和组成. 可以简介为下图所示
根据主键查询是在 Page Directory中进行二分搜索确定该数据所在的槽, 然后通过该槽偏移量确定页, 往后遍历查找数据
但是这是主键查询, 索引的原理也相同
ps: 基础直接跳过
索引
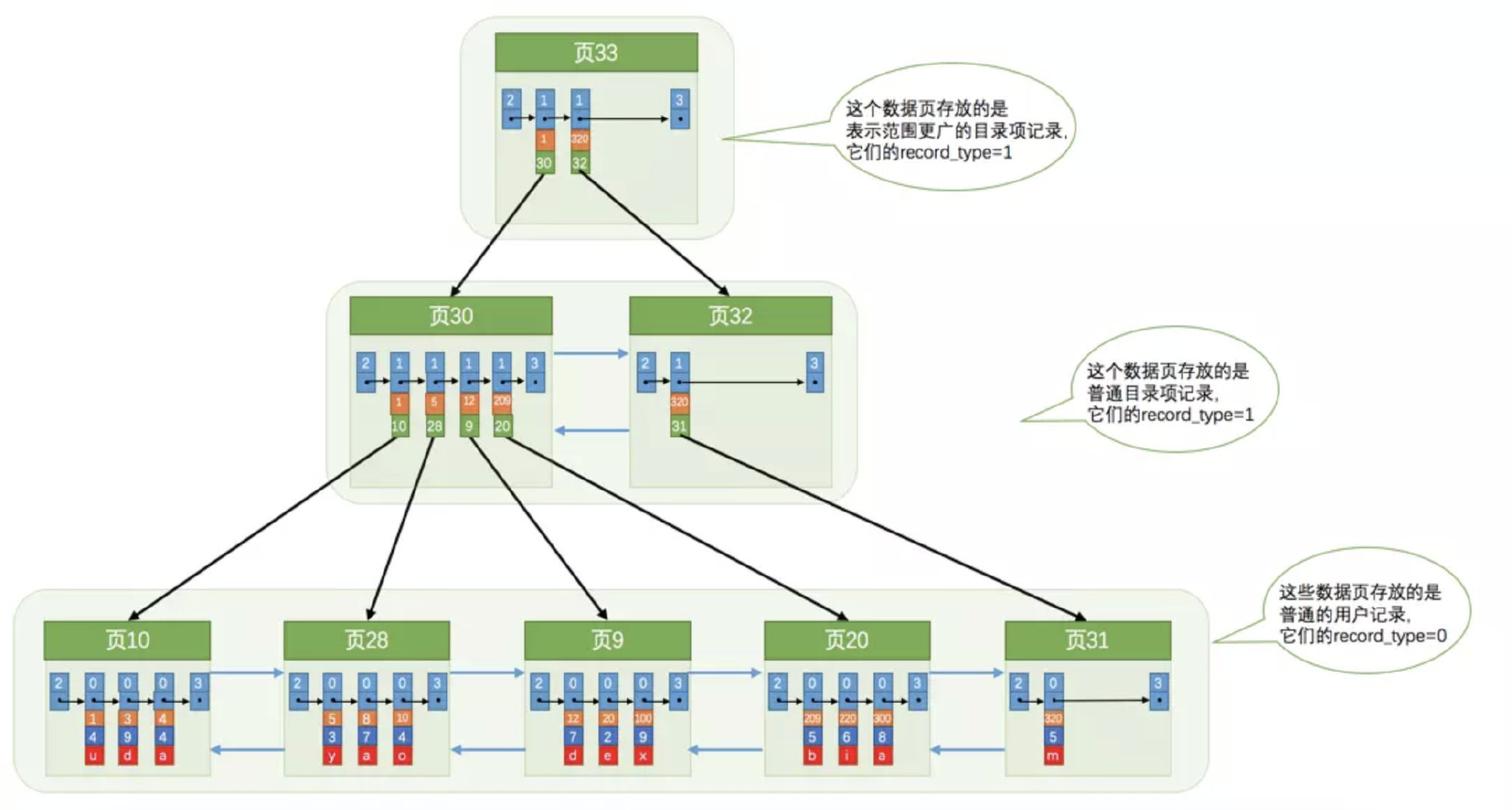
在之前我们了解的主键查询是通过主键进行排序. 那么我们索引是利用我们的索引字段充当主键
下面其实就是主键索引, 又称聚簇索引, 橙色为主键, 绿色为对应的页
在非叶子节点的 record_type 都为 1 (表示为目录), 叶子节点的record_type 为 0 (表示为数据节点)我们回顾一下一个页为 16KB, 假设一个页可以存放100 条记录(实际大部分场景远大于 100 条, 如果按照 100 条来算, 可以理解为每条数据 163 字节)
一层节点 100 ^ 1 条数据
两层节点 100 ^ 2 = 10000 条数据
三层节点 100 ^ 3 = 1000000 条数据
四层节点 100 ^ 4 = 100000000 条数据
聚簇索引
非聚簇索引
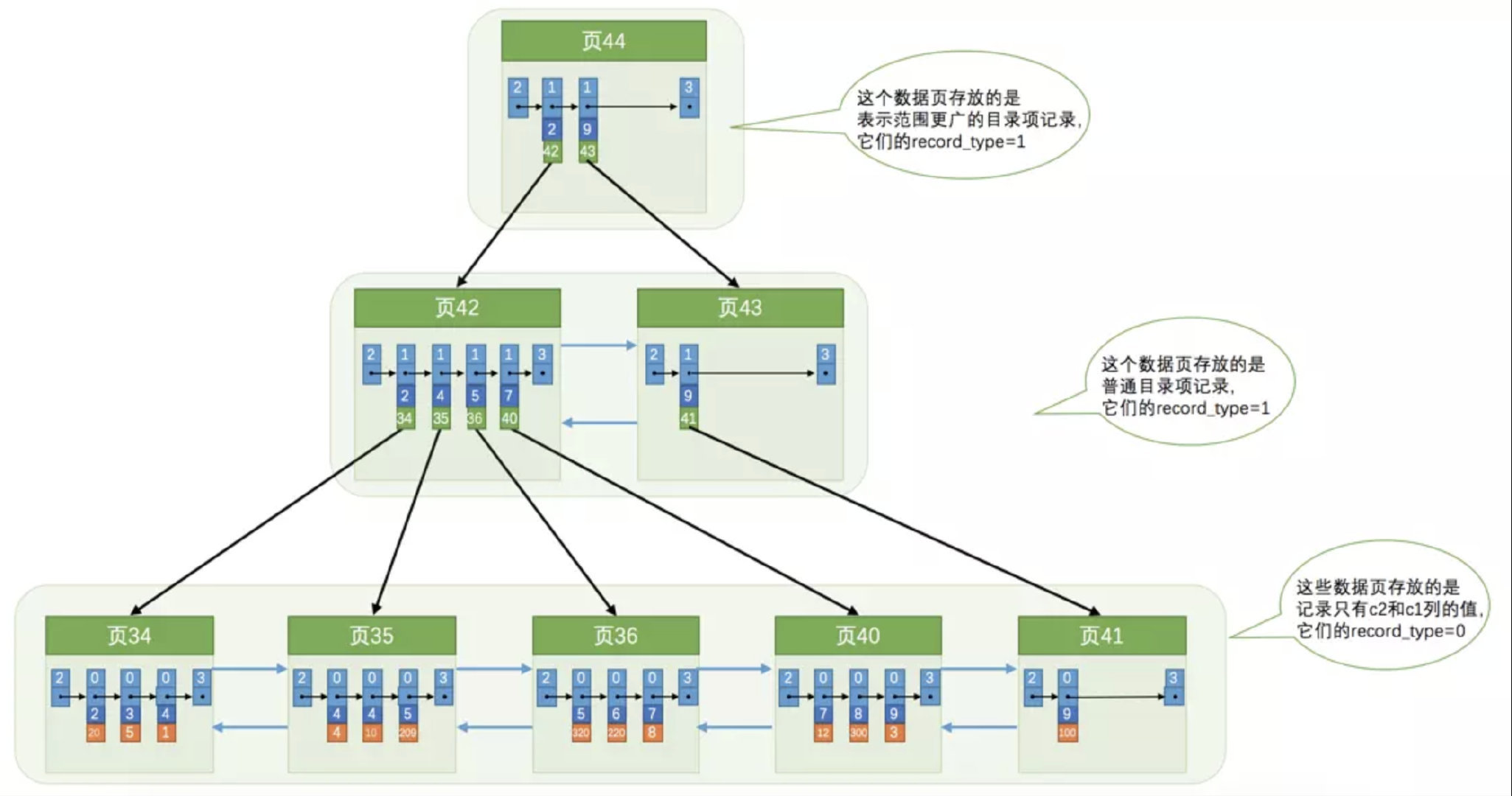
普通索引
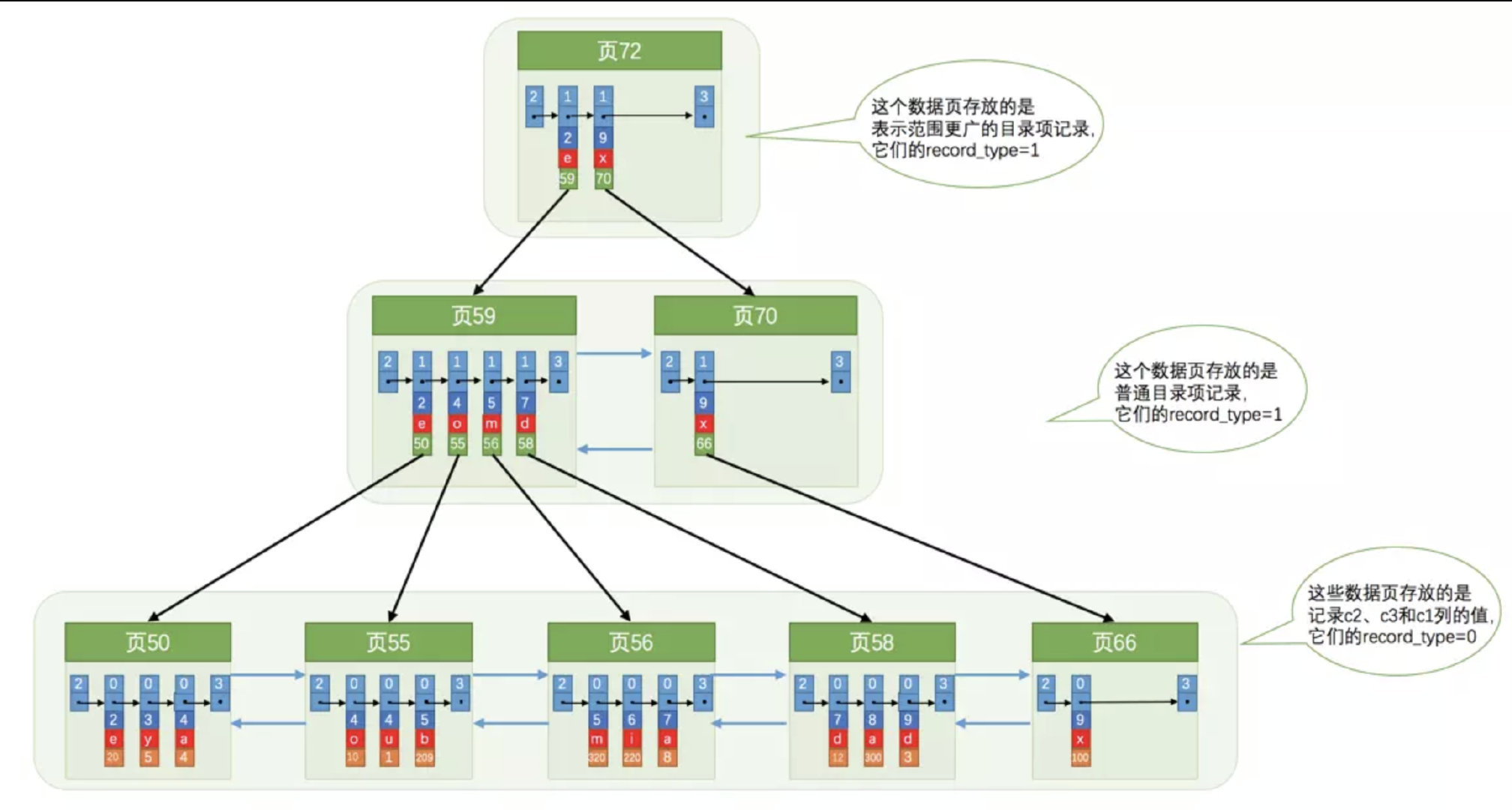
联合索引
聚簇索引和非聚簇索引的区别就是, 聚簇索引的叶子节点保存所有数据, 非聚簇索引保存的是索引字段和主键(回表查询全量数据)
普通索引和联合索引的区别就是, 普通索引的用户数据只保存索引字段和页节点, 联合索引的用户数据为多个索引字段和页节点
联合索引中的字段值依次排序
页分裂情况
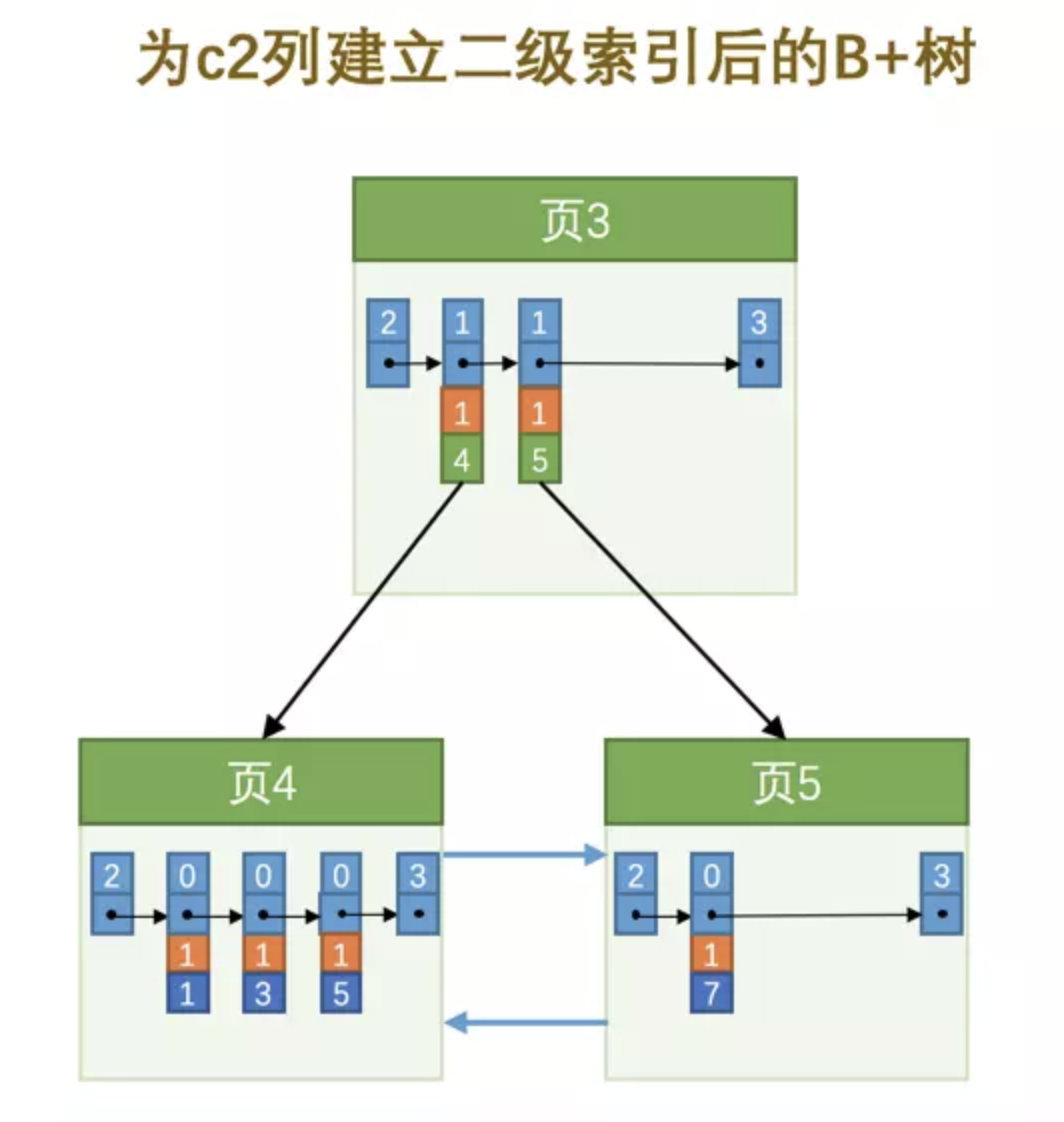
考虑在上述情况下, 如果在插入相同 1 的数据是应该放在页 4 还是页 5 ?虽然是可以推到出放在页 5, 但是为了更加优化, 我们在非叶子节点中还是放入当前数据指向页的最小主键, 这样我们能更加清晰的知道是放在页 5, 如下图
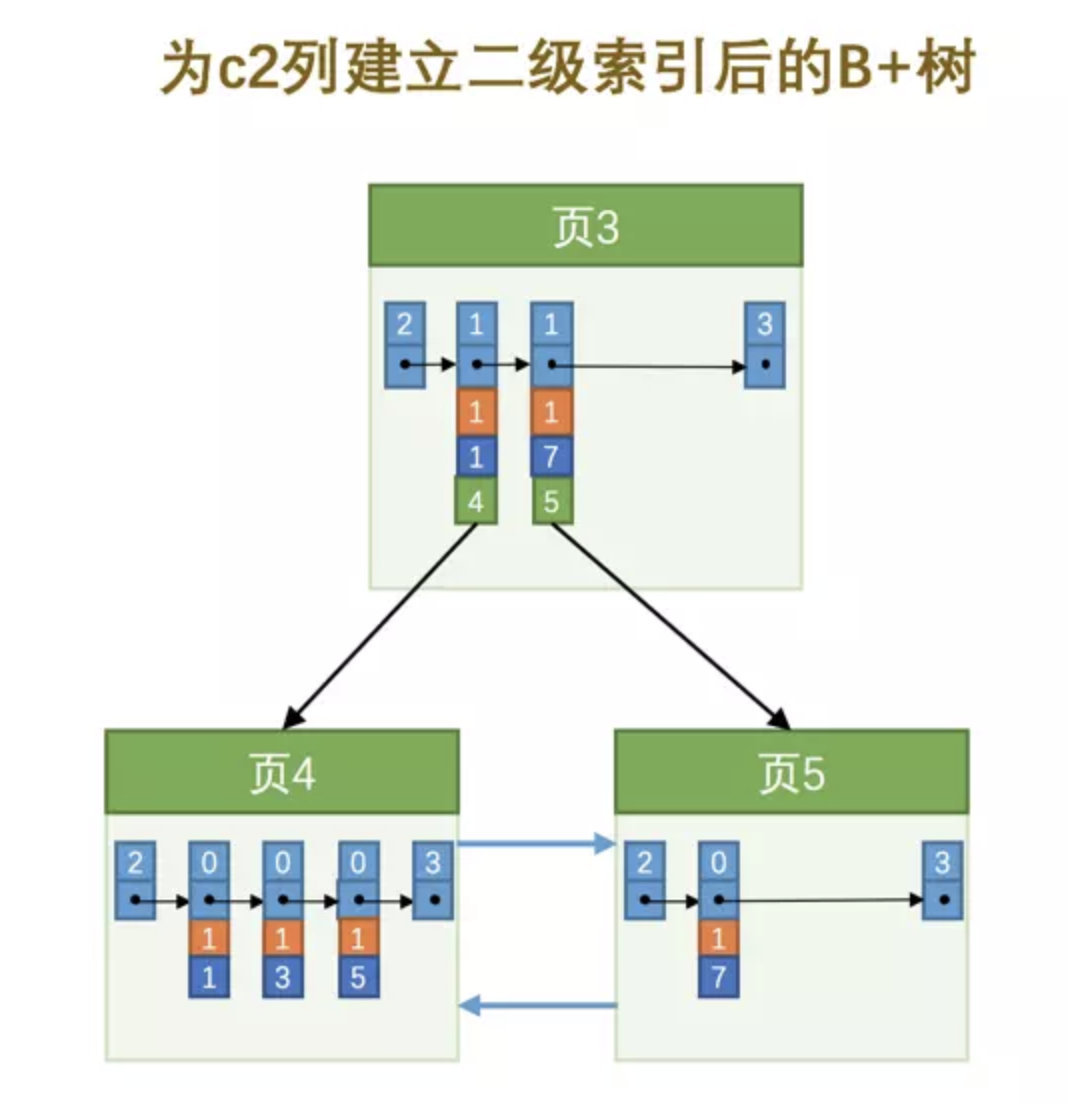
另外, 我们之前已经说过, 一个页最少要放入两条数据
原因: 如果每个页只能可以存放两条数据, 在查询效率上, 每次能筛选掉一半的数据. 如果允许存放一条数据, 那么相当于要全部遍历
覆盖索引
覆盖索引并不是一种索引. 只是一种优化手段
如果一次查询所需要返回的字段在该索引中能够满足, 那么就不需要回表, 直接返回. 该方式即为覆盖索引(因为正常查询所有数据, 是需要通过非聚簇索引查到主键, 再回表查询聚簇索引获取全量数据)
如果确定索引列
选择基数大的列 (可以理解为去重后的数量)
举例:
如果是性别列, 只有三个值: 男, 女, 第三性别. 那么基数即为 3
如果是时间秒值, 那么一天会有 86400. 那么基数即为 86400
选择性别列, 可能根据索引确定后, 依然有大量数据, 但是根据时间秒值, 能筛选掉大量的数据
同样. 如果 MySQL 优化器发现该索引筛选后的数据依然很大, 那么会选择走全表扫描
索引类型尽可能小
一个页的大小为 16KB, 如果类型尽可能小, 那么一个页存放的数据就会更多, 相同的索引数据层数就会更少, 占用空间也小
索引使用
因为比较基础, 就直接总结
B+树索引在空间和时间上都有代价,所以没事儿别瞎建索引。B+树索引适用于下边这些情况:
- 全值匹配
- 匹配左边的列
- 匹配范围值
- 精确匹配某一列并范围匹配另外一列
- 用于排序
- 用于分组
- 在使用索引时需要注意下边这些事项:
- 只为用于搜索、排序或分组的列创建索引
- 为列的基数大的列创建索引
- 索引列的类型尽量小
- 可以只对字符串值的前缀建立索引
- 只有索引列在比较表达式中单独出现才可以适用索引
- 为了尽可能少的让
聚簇索引发生页面分裂和记录移位的情况,建议让主键拥有AUTO_INCREMENT属性。- 定位并删除表中的重复和冗余索引
- 尽量使用
覆盖索引进行查询,避免回表带来的性能损耗。
访问方法
const
利用主键或唯一索引的等值匹配, 结果只会是一个值
IS NULL 并不是 const
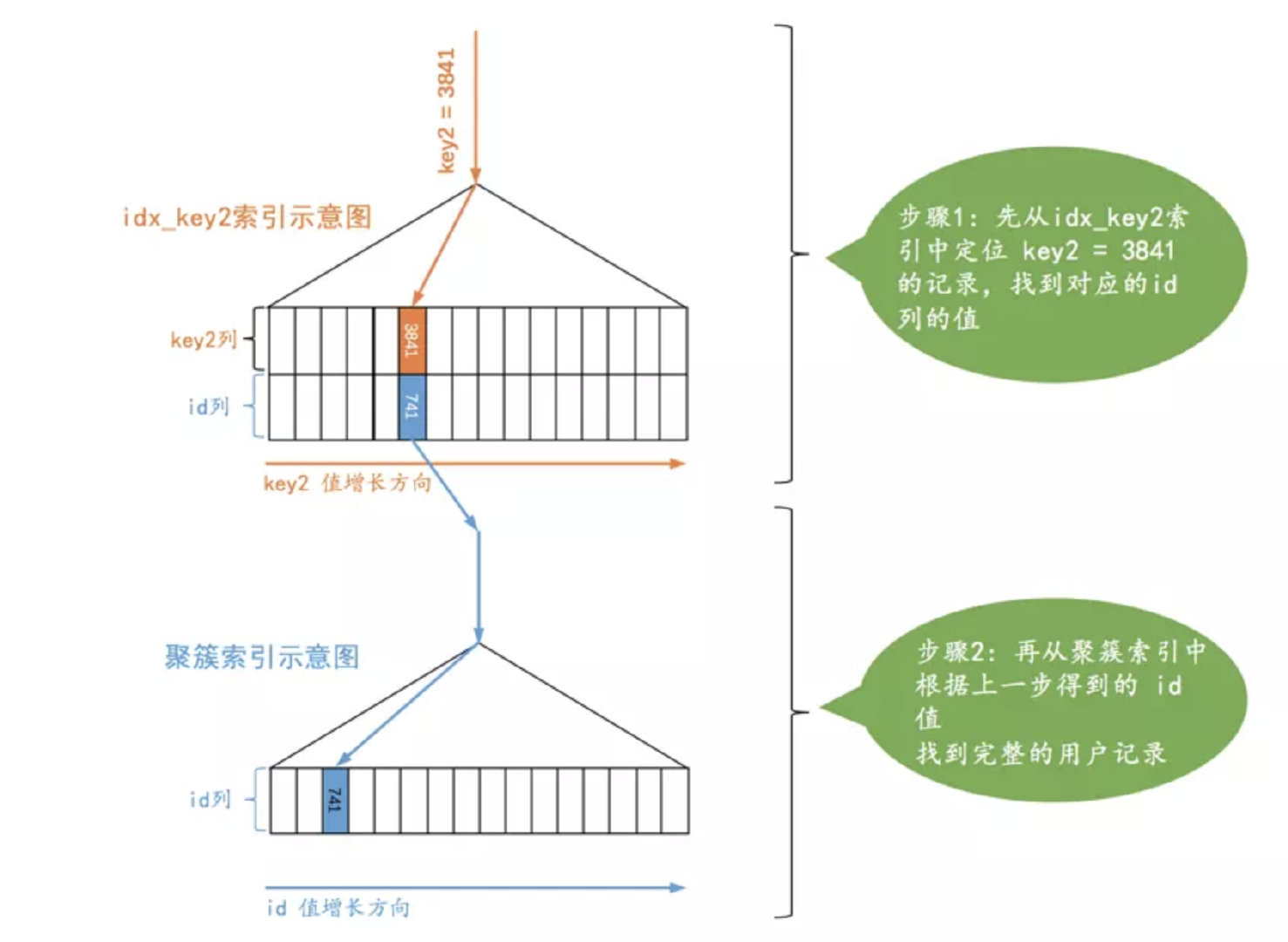
ref
利用索引的等值匹配, 结果可能为多个值 (因为一个 key 可能对应多个 value)

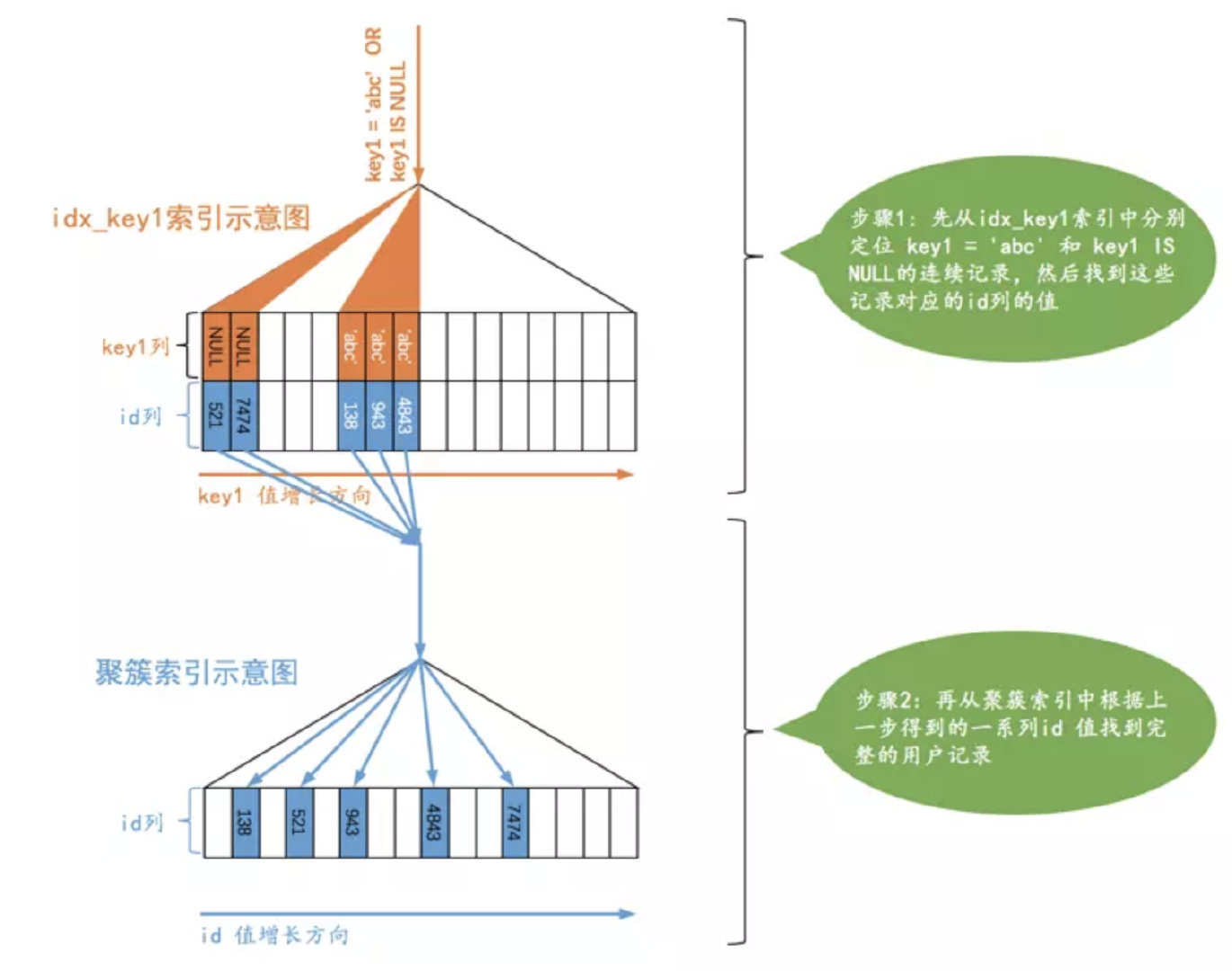
ref_or_null
上述再加上 null 的判断
range
范围查询
SELECT * FROM single_table WHERE key2 IN (1438, 6328) OR (key2 >= 38 AND key2 <= 79);
index
SELECT key_part1, key_part2, key_part3 FROM single_table WHERE key_part2 = ‘abc’;
key_part2 没有索引, 但是可以通过遍历 key_part1_key_part2_key_part_3 来匹配结果, 这样的方式要比全表扫表成本小很多, 因此采用二级索引遍历的方式叫做 index
all
全表扫描
注意
select * from table where a = ‘’ or b = ‘’
OR 只有 a 和 b 都有索引, 并且是等值查询时, 才会使用 UNION