分布式系统一致性算法 - Raft
简介
Raft是用于管理复制日志的共识算法. 它产生的结果等效于 multi-Paxos, 它的效率与Paxos相同, 但其结构与Paxos不同. 这使Raft比Paxos更易于理解, 并且为构建实用系统提供了更好的基础. 为了增强可理解性, Raft分离了共识的关键要素, 例如领导人选举, 日志复制和安全性, 并强制实施了更高程度的一致性以减少必须考虑的状态数. 一项用户研究的结果表明, 与Paxos相比, 筏更易于学生学习. Raft还包括用于更改集群成员资格的新机制, 该机制使用重叠的多数来保证安全
基础概念
流程
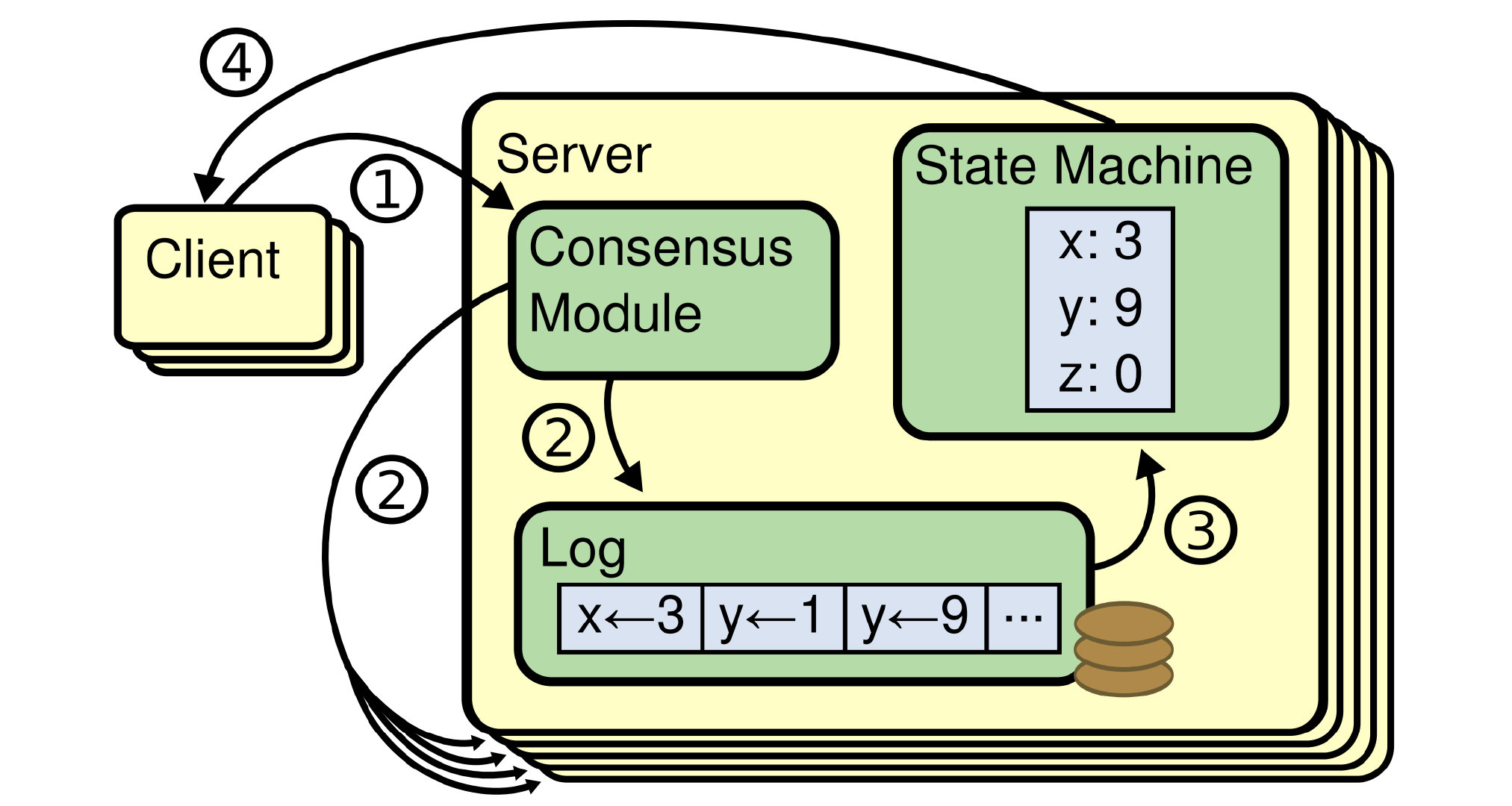
状态机: 对外保证一致性的数据
日志: 保存了所有修改记录
一致性模块: 一致性模块算法就是用来保证写入的log的命令的一致性(核心内容)
客户端发起更新请求 -> leader 发起同步事件(append) -> 同步完成(commit) -> 应用状态机(apply) -> 返回客户端
ps: 如果超时, 客户端将带着 requestId 重试. 同样, leader 发起同步事件也是幂等操作

节点状态
所有节点持久化的属性:
- currentTerm: 服务器的最新term(首次启动时初始化为0, 单调增加)
- votedFor: 在当前任期内获得投票的候选人ID(如果没有, 则为null)
- logs[]: 本地日志(索引从 1 开始)
所有节点非持久化的属性:
- commitIndex: 已提交(过半 follower 同步的日志)的最高日志条目的索引(初始化为0, 单调增加)
- lastApplied: 应用于状态机的最高日志条目的索引(初始化为0, 单调增加, 一定小于等于 commitIndex)
leader 的属性:
- nextIndex[]: 各个 follower 节点同步的下一个节点(初始化为leader 的最大索引)
- matchIndex[]: 各个 follower 节点的匹配节点(这个位置之前的日志所有节点都是一致的, 初始化为 0)
规则:
- 如果 commitIndex > lastApplied, 则说明需要将已同步的日志应用于状态机, 然后更新 lastApplied
- 如果 同步事件返回的 term > currentTerm, 则退回为 follower(此时状态为 leader 或者 candidate)
leader
副本集中只会存在一个 leader. leader 负责客户端的所有更新请求.
规则:
- 成为 leader 后, 发送心跳事件给所有服务, 防止重复选举
- 从收到客户端指令, 同步 follower 并且 apply 状态机后, 相应客户端
- 如果 follower 的last log index ≥ nextIndex, 则说明 follower 之前的日志需要替换, 将该 follower 的 nextIndex-1 再同步该 follower(重复直到相同, 保证 follower 的数据和 leader 一致)
- 如果同步数据成功, 则需更新对应 follower 的 nextIndex 和 matchIndex
- 如果过半 follower 的 commitIndex > N, 则将 commitIndex 更新为 N
follower
普通副本, 接收leader 的更新请求, 更新 log
candidate
选举者. 当探活发现和 leader 断联, 则从 follower 状态切换为 candidate, 发起选举
log
更新记录
事件
AppendEntries RPC
leader 发起的同步日志事件和心跳事件(心跳extries 为空)
参数:
- term: leader 任期号(递增)
- leaderId: leader id(方便客户端发起更新请求, 重定向至 leader 节点)
- prevLogIndex: 同步日志的前一条日志索引(安全校验, 保证前一个元素下标相同)
- prevLogTerm: 同步日志的前一条日志元素(安全校验, 保证前一个元素相同)
- entries[]: 同步的日志列表
- leaderCommit: leader 的 commitIndex(如果 follower 小于 leader, 则同步为 leader 的 commitIndex, 并将区间的日志 apply 状态机)
结果:
- term: 当前节点的 leader 任期号
- success: 是否成功
如果 term < currentTerm, 则说明 leader 已失效, 返回 false 让他更新为 follower 状态
如果 prevLogIndex 的 prevLogTerm 和本地的不一致, 则说明本地的数据需要同步为 leader 的数据, 返回 false. 让 leader 索引前移再来请求
其他情况则将本地数据替换为 leader 数据
如果leaderCommit > 本地 commitIndex, 则说明数据已 commit, 需要将本地的 commitInde x更新为leaderCommit
RequestVote RPC
candidate 发起的投票选举事件
参数:
- term: 候选人任期
- candidateId: 候选人 Id
- lastLogIndex: 候选人最新日志索引
- lastLogTerm: 候选人最新的日志元素
结果:
- term: follower 的 term
- voteGranted: true 则说明投票给候选人
如果 term 小于 当前 follower term 则说明该候选人没有当前 follower 日志更新, 返回 false
如果 lastLogIndex 小于当前 follower 日志索引, 则说明已经有更新的 leader, 返回 false
如果 lastLogTerm 和当前 follower 日志元素不同, 则返回 false
选举
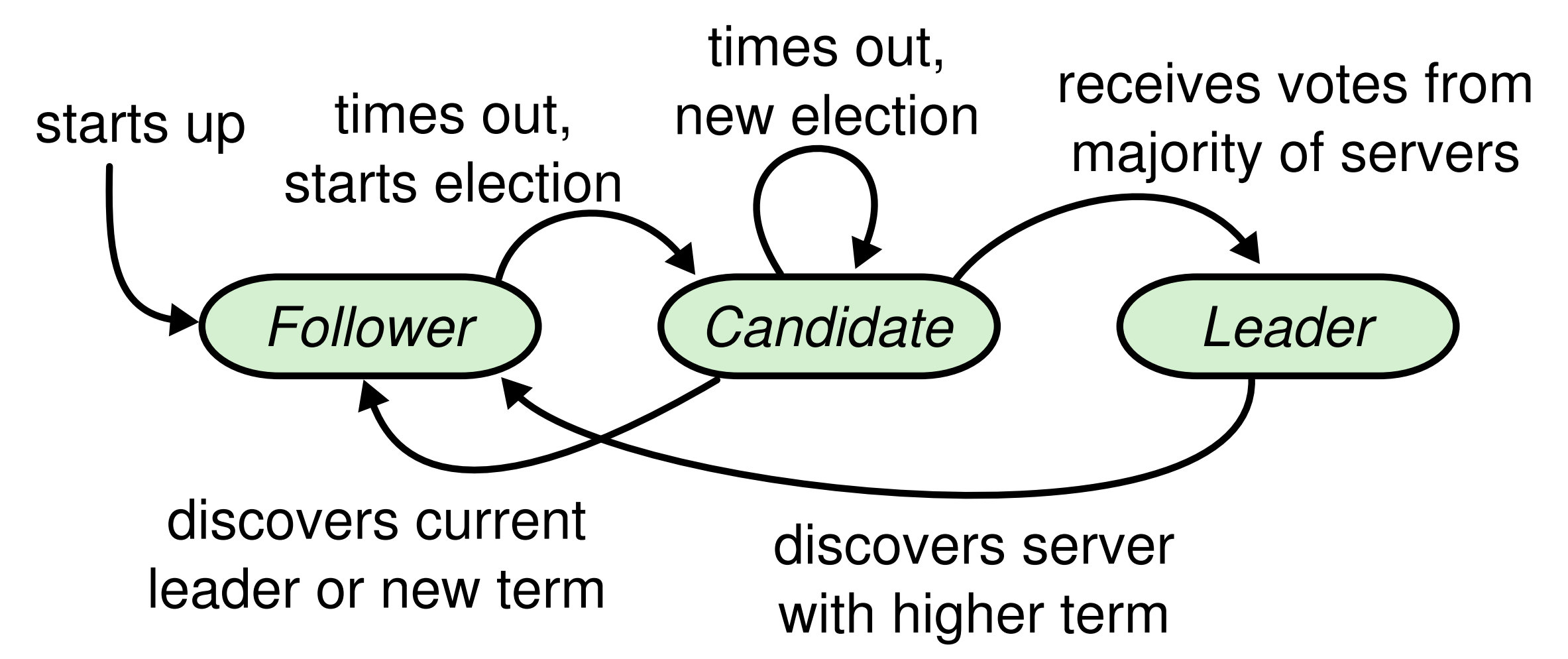
选举超时事件为一个固定区间的随机值(最大限度降低竞争)
节点的每个 term 至允许投票一次(先到先得)
candidate 当接收到 leader 的 term > currentTerm, 则退回 follower
cndidate 当接收到 leader 的 term < currentTerm, 则拒绝同意, 等待超时, 重新发起选举
- 首先所有节点初始化都为 follower, 并且启动定时器, 超时没有收到消息, 则需要转换状态为 candidate,
- 将 currentTerm(初始化为 0) + 1并且发起投票选举事件
- 如果赢得选举, 则切换为 leaderl 状态
- 其他节点赢得选举, 则自己变为 follower
- 没有获胜者, 则等待然后currentTerm + 1, 再次发起投票选举事件
快照(日志压缩)
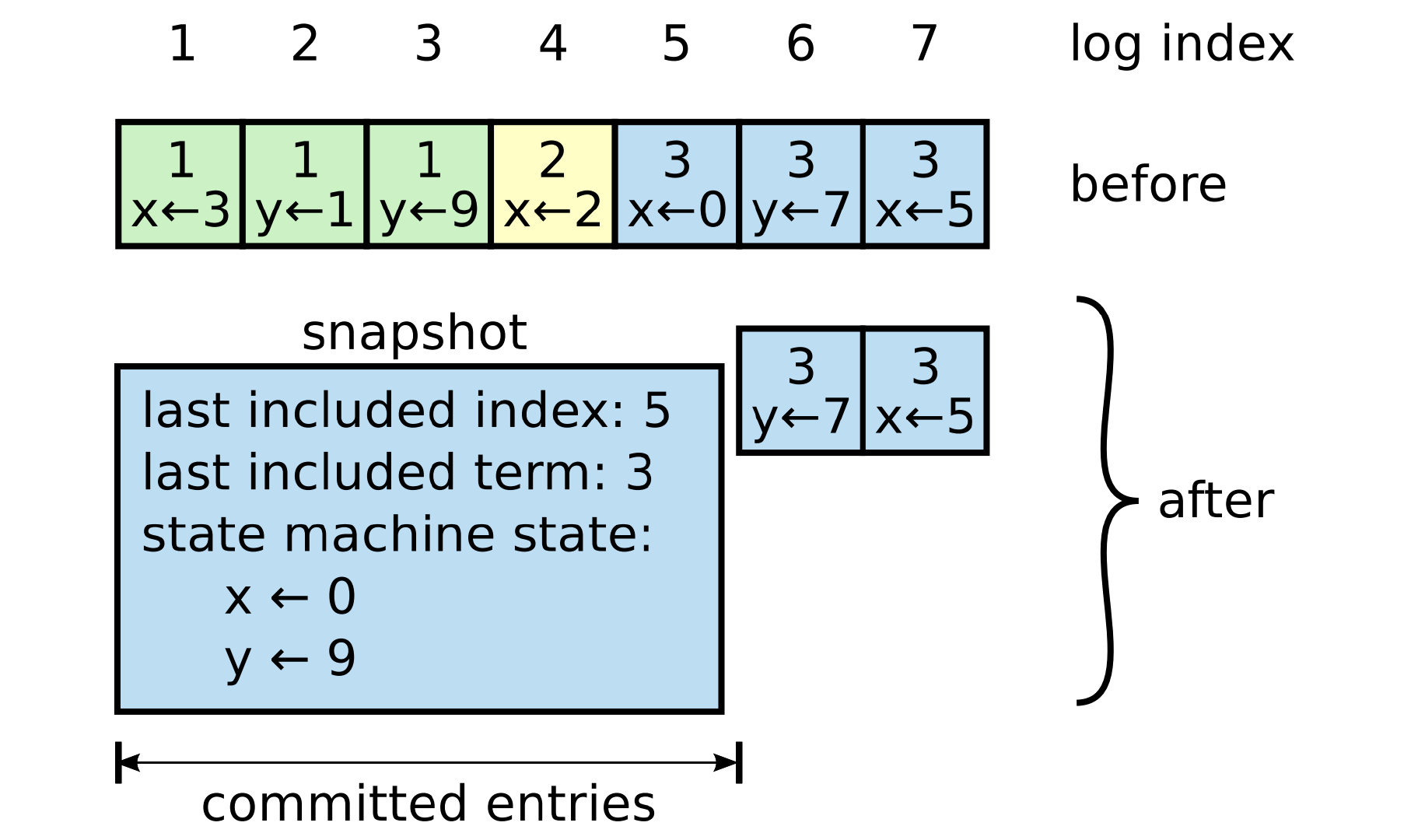
随着时间推移, 日志一定会无比巨大, 如果有一个 follower 和 leader 日志差异较大, 则需要leader 一直回退 nextIndex 重试, 效率低下. 并且由于状态机不关注过程, 只在乎最终态, 因此可以定期将状态机的数据生成快照, 来提升启动效率和节省磁盘空间(可参考 Redis 持久化方式 rdb 和 aof 思想)
快照可由 follower 自己生成(降低由 leader 发送至 follower 的网络占用), 也可有 leader 发送至 follower(当 follower 落后过多时)
如果 leader 发送的 follower 的最后一条日志在 follower 中存在, 则 follower 可放弃该快照
由于生成 snapshot 涉及 IO 操作, 为了提高效率采用 COW(CopyOnWrite)来保证生成快照期间的日志同步同样不会丢失
leader 发送快照

leader 发送同步快照事件
参数:
- term: 当前任期
- leaderId: leaderId
- lastIncludedIndex: 快照的最后一个索引
- lastIncludedTerm: 快照的最后一个元素
- offset: 快照文件中块所在位置的字节偏移量
- data[]: 快照块的原始字节,从偏移量开始
- done: 如果这是最后一块, 则为 true
结果:
- term: 当前节点的 leader 任期号
如果term <currentTerm,请立即回复
如果第一个块(偏移量为0),则创建新的快照文件
以给定的偏移量将数据写入快照文件
如果done为false,则回复并等待更多数据块
保存快照文件,丢弃索引较小的任何现有或部分快照
如果现有日志条目的索引和术语与快照的最后一个包含的条目相同,请保留其后的日志条目并回复
丢弃整个日志
使用快照内容重置状态机(并加载快照的集群配置)
案例
简单同步
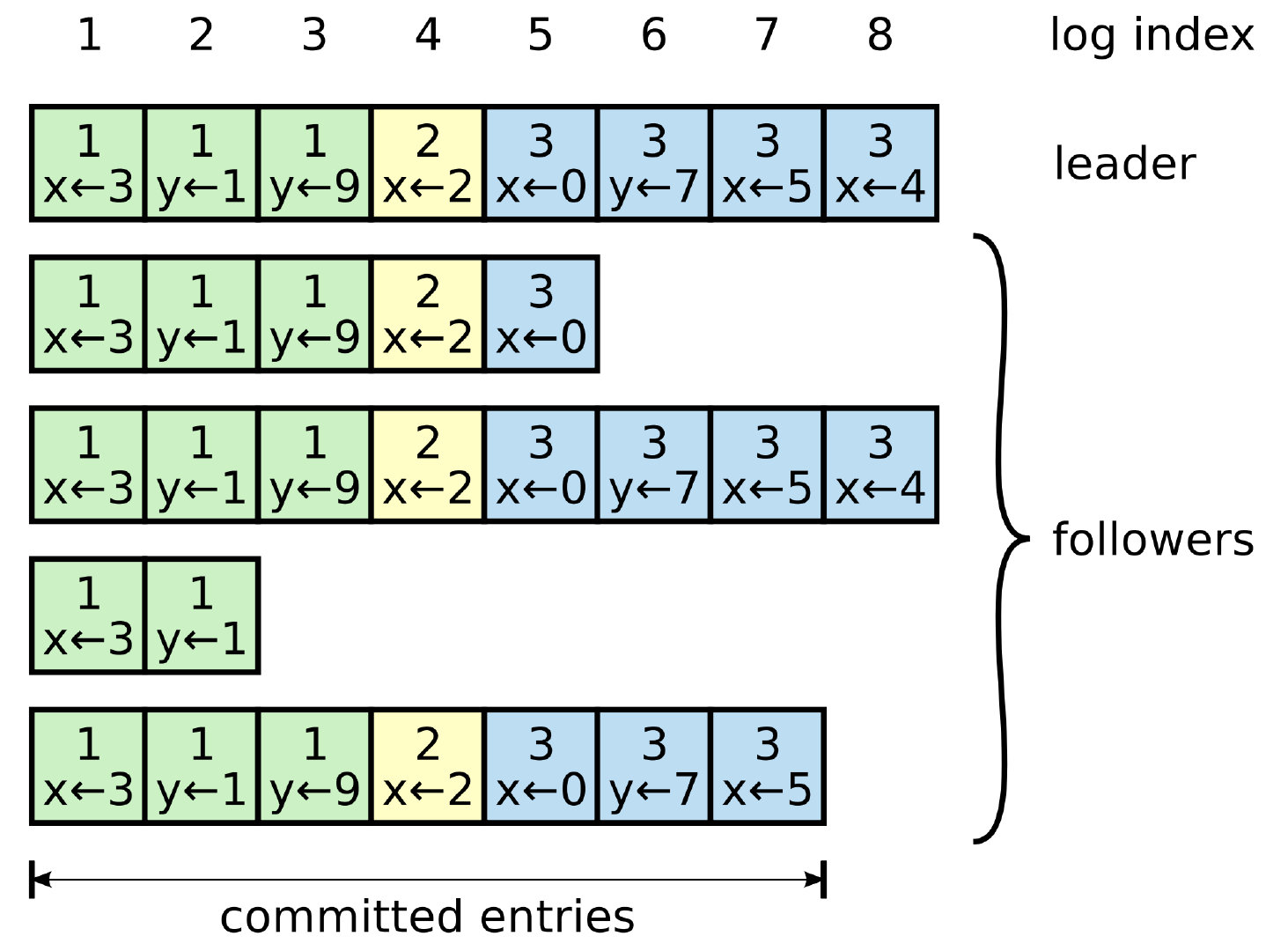
假设 leader 一直未变动(实际发生三次选举, 只不过每次同步数据过程没有数据同步冲突). 各个节点的同步情况可能如上图情况. 此时第 2, 4, 5 节点可能因为网络原因导致未跟上 leader 的同步. 假设此时 leader 发起同步, leader 的第二个节点logIndex[1].index = 8 , 那么他会发起同步事件给第二个节点, 第二个节点会返回 false, 此时 leader 将第二个节点logIndex[1].index - 1 = 7, 再次发起同步事件, 还会 false, 直到 index = 5, 此时第二个节点才会执行同步, 返回 true
复杂同步
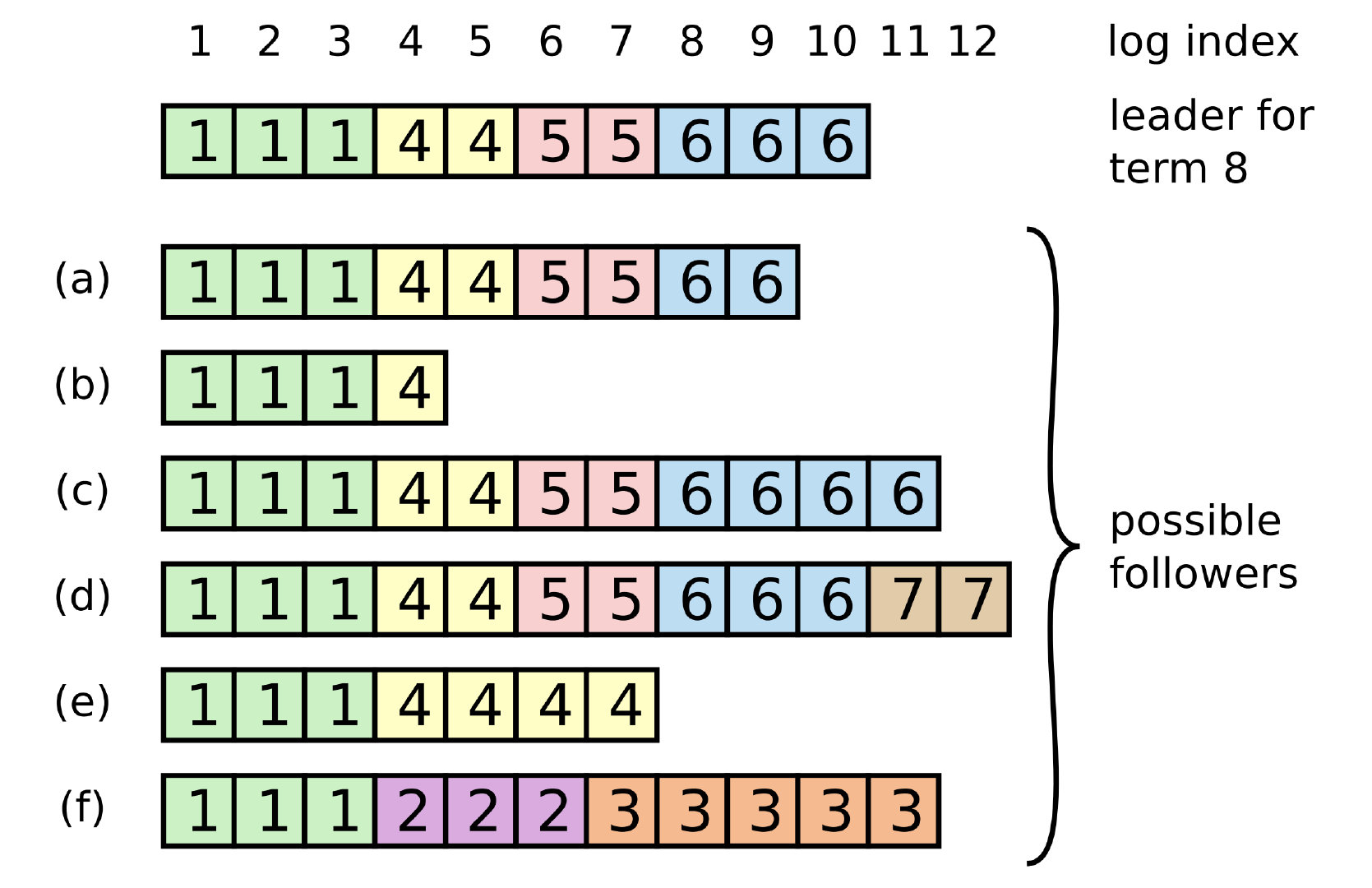
最复杂的情况为上图. 图中可得总过发生过 7 次选举. 观察 f 可发现, 可得出 term = 2 时, 追加了 222, 然后再次发生选举, term = 3, 追加33333 日志, 但是两次皆未同步至其他节点(也可能是没有过半节点同步, 导致新的选举节点将数据同步覆盖)便宕机, 此时选举结果为 term = 4, 并且a, b, c, d, e皆同步数据. 此时又发生选举 term = 5 -> 6, 当 leader 变为 7 时(仍然数据未同步过半)宕机, 发生选举重新回到 leader(最上方, 即将为 term = 8). 此时 leader 发起数据同步, 会将其他节点数据同步为leader 数据. 至于 d, f 节点的数据将会重置并覆盖